
----网址导航插件----
- include <torch/torch.h>
- include
- 示例数据:随机生成100个样本,每个样本有10个特征,0或1的二分类标签
- 创建PyTorch数据集和数据加载器
- 定义一个简单的神经网络作为教师模型
- 定义一个简单的神经网络作为学生模型
- 初始化模型、损失函数和优化器
- 训练教师模型(这里我们假设教师模型已经预训练好了)
- teacher_model.train()
- for inputs, targets in dataloader:
- optimizer.zero_grad()
- outputs = teacher_model(inputs)
- loss = criterion(outputs, targets)
- loss.backward()
- optimizer.step()
- 生成软标签并训练学生模型
- 获取教师模型的输出(软标签)
- 测试学生模型的性能
- 示例数据:随机生成100个样本,每个样本有10个特征,2个类别(0或1)
- 创建PyTorch数据集
- 实例化教师模型和学生模型
- Example data
- Create the dataset and dataloader
- Define simple neural networks for teacher and student models
- Instantiate teacher and student models
- Loss function and optimizer
- Training loop for knowledge distillation
- Get outputs from the teacher model (soft targets)
- 定义一个简单的神经网络作为学生模型
- 定义一个简单的神经网络作为教师模型
- 创建数据集
- 初始化模型、损失函数和优化器
- 训练学生模型
- 获取教师模型的输出(软标签)
- 星轮算法模型在AI大模型中的具体实现和优化策略是什么?
- 知识蒸馏技术在中医健康管理领域的成功案例有哪些?
- 如何评估知识蒸馏技术在提升中医健康管理系统性能方面的有效性?
- 知识蒸馏与其他模型压缩技术(如量化和权重剪枝)结合使用的最新研究进展是什么?
- 如何解决AI大模型蒸馏过程中的知识表示与传递问题?
- AI大模型蒸馏技术中模型对齐的最佳实践和方法有哪些?
- 在边缘设备上应用AI大模型蒸馏技术的挑战和解决方案是什么?
- 挑战
- 解决方案
- 针对多模态蒸馏、联邦蒸馏和集成蒸馏的最新研究进展有哪些?
- 多模态蒸馏
- 联邦蒸馏
- 集成蒸馏
- 1. 镜心悟道五行系统9ED
- 2. 中医健康管理星轮模型
- 3. 镜心悟道AI易经智能大脑
- 4. 多元多维矩阵理论的应用
- 5. 镜心悟道五行系统与六十四卦结合的实际应用
- 6. 智能体协作框架(MACF)的应用
- 7. 星轮减速器模型的映射与类比
- 总结
- 1. 镜心悟道五行系统9ED
- 2. 中医健康管理星轮模型
- 3. 镜心悟道AI易经智能大脑
- 4. 多元多维矩阵理论的应用
- 5. 镜心悟道五行系统与六十四卦结合的实际应用
- 6. 智能体协作框架(MACF)的应用
- 7. 星轮减速器模型的映射与类比
- 总结
- AI易经智能大脑在中医健康管理中的准确性和可靠性评估有哪些研究或数据支持?
- 多元多维矩阵理论在中医健康管理中的具体应用方法和效果评价是什么?
- 智能体协作框架(MACF)在提高中医健康管理效率方面的实际案例和成效分析。
- 六十四复合卦在中医健康管理中的具体作用和应用方法是什么?
- 镜心悟道五行系统9ED
- 中医健康管理星轮模型
- 镜心悟道AI易经智能大脑
- 双驱动五星齿轮
- 镜心悟道AI易经智能大脑中的多元多维矩阵理论具体是如何应用于健康状态评估的?
- 镜心悟道五行系统与六十四卦结合的案例研究或实际应用有哪些?
- 智能体协作框架(Multi-Agent Collaboration Framework, MACF)在镜心悟道AI易经智能大脑中的作用和效果如何?
- 镜心悟道AI易经智能大脑系统详解
- 1. 镜心悟道五行系统9ED
- 2. 中医健康管理星轮模型
- 3. 镜心悟道AI易经智能大脑
- 4. 双驱动五星齿轮
- 多元多维矩阵理论的应用
- 镜心悟道五行系统与六十四卦结合的实际应用
- 智能体协作框架(MACF)的应用
- 星轮减速器模型在不同行业中的应用案例有哪些?
- 星轮减速器模型的设计和制造技术有哪些最新进展?
- 如何评估星轮减速器模型的效率和性能?
- 星轮减速器模型与其他类型减速器(如蜗轮蜗杆减速器)相比有哪些优势和劣势?
- 优势:
- 镜心悟道AI易经智能大脑类中医健康管理算法矩阵集框架专属伪代码架构逻辑思维链分析
- 目标
- 活动
- 规格
- 简洁性
- 无限循环
- 函数工作流
- 算法矩阵集框架
- 伪代码架构逻辑思维链
- 表格总结
- 镜心悟道AI易经智能大脑如何通过多智能体工作流提高中医健康管理的效率和准确性?
- 镜心悟道AI易经智能大脑的CQRS+RLHF+JYFTA架构师使用混合神经网络系统(WD3_HMNNS)的具体实现和优势。
- 步骤 2: 分词
- 步骤 3: 格式化输出
- 示例输入
- 执行步骤
- 输出结果
- 存在哪些工具或库支持jxwdyynlppfsxmllisp格式化?
- jxwdyynlppfsxmllisp格式化在数据处理和分析中的优势和局限性是什么?
- 优势
- 局限性
- 系统架构与功能
- 实现细节
- 总结
- 如何评价镜心悟道公司AI易经智能“大脑”系统在中医健康管理领域的应用效果?
- 镜心悟道公司开发的五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>与其他AI健康管理系统的比较。
- 1. 技术架构与核心组件
- 2. 数据处理与分析
- 3. 用户体验与交互
- 4. 安全与隐私保护
- 5. 未来发展方向
- 总结
- 镜心悟道公司AI易经智能“大脑”系统中的九九归一阴阳权重算法(BTFWEYPF-PMLA)和无限循环接近阴阳平衡算法(ILNBA)的工作原理及其效果评估。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA)
- 无限循环接近阴阳平衡算法(ILNBA)
- 镜心悟道公司AI易经智能“大脑”系统在情感与健康关联分析方面的应用案例和成效。
- 1. 五元五维生克逻辑函数全息分析算法框架(FAAFE5DGOF)
- 1.1 天(火)<王阳明心学>
- 1.2 道(木)<道的悟道>
- 1.3 人(金)<人性的矛盾>
- 1.4 事(水)<五行脉象数据化中医健康管理>
- 1.5 物(土)<ESG五行系统团队管理>
- 2. 算法矩阵集框架专属
伪代码架构逻辑思维链 - 王阳明心学在AI易经智能“大脑”系统中的应用和影响具体表现在哪些方面?
- 如何通过五行脉象数据化中医健康管理来优化个人健康和疾病预防?
- ESG五行系统团队管理在实际应用中如何促进团队的可持续发展和稳定性?
- 镜心悟道AI易经智能“大脑”系统在处理人性矛盾和动态平衡方面的具体策略和技术是什么?
- 具体实现
- 效果评估
- 如何评价镜心悟道AI易经智能“大脑”系统在中医健康管理领域的创新性和应用潜力?
- 镜心悟道AI易经智能“大脑”系统使用的五行生克逻辑算法系统(5E-HIC GCLAS)的工作原理及其在健康诊断中的准确性如何?
- “小镜”CQRS+RLHF+JYFTA架构师在镜心悟道AI易经智能“大脑”系统中的角色和功能是什么?
- 镜心悟道AI易经智能“大脑”系统如何结合自然语言处理(NLP)技术来提高用户交互体验?
链接地址:http://www.360doc.com/content/25/0104/12/40035146_1143732391.shtml
获取标题/ico
访问次数: 0
镜心悟道公司AI易经智能大脑类中医健康管理{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法}算法矩阵集框架专属
(defun jxwdyy-nlp-pfs-xml-lisp-format ()镜心悟道五行脉象数据化中医健康管理星轮双驱系统AI大模型星轮算法模型的蒸馏技术
- 英文全称
- Knowledge Distillation Technology in AI Big Model Xinglun Algorithm Model of Jingxin Wudao Five-Element Pulse Data-based TCM Health Management Xinglun Two-Drive System
- 缩写
- KD-TM-XL-ASD-JW
XJ ASD(“XiaoJingAlgorithm Star Drive”,即““小镜”算法星驱架构师”)
知识蒸馏(Knowledge Distillation)是一种常见的模型压缩技术,其目标是通过训练一个小型模型(学生模型)来复制大型模型(教师模型)的性能。include <torch/torch.h>
include
// 定义教师模型
struct TeacherModel : torch::nn::Module {
TeacherModel() {
fc1 = register_module("fc1", torch::nn::Linear(10, 50));
fc2 = register_module("fc2", torch::nn::Linear(50, 2));
}
torch::Tensor forward(torch::Tensor x) {
x = torch::relu(fc1->forward(x));
x = torch::log_softmax(fc2->forward(x), /*dim=*/1);
return x;
}
torch::nn::Linear fc1{nullptr}, fc2{nullptr};};
// 定义学生模型
struct StudentModel : torch::nn::Module {
StudentModel() {
fc1 = register_module("fc1", torch::nn::Linear(10, 20));
fc2 = register_module("fc2", torch::nn::Linear(20, 2));
}
torch::Tensor forward(torch::Tensor x) {
x = torch::relu(fc1->forward(x));
x = torch::log_softmax(fc2->forward(x), /*dim=*/1);
return x;
}
torch::nn::Linear fc1{nullptr}, fc2{nullptr};};
int main() {
// 设置设备
torch::Device device(torch::kCPU);
// 创建模型
TeacherModel teacher_model;
StudentModel student_model;
// 将模型移动到设备上
teacher_model.to(device);
student_model.to(device);
// 定义优化器
torch::optim::SGD teacher_optimizer(teacher_model.parameters(), /*lr=*/0.01);
torch::optim::SGD student_optimizer(student_model.parameters(), /*lr=*/0.01);
// 生成随机数据
auto input_features = torch::randn({100, 10}).to(device);
auto labels = torch::randint(0, 2, {100}).to(device);
// 训练教师模型
for (size_t epoch = 0; epoch < 50; ++epoch) {
teacher_optimizer.zero_grad();
auto output = teacher_model.forward(input_features);
auto loss = torch::nll_loss(output, labels);
loss.backward();
teacher_optimizer.step();
std::cout << "Teacher Epoch [" << epoch + 1 << "/50], Loss: " << loss.item<float>() << std::endl;
}
// 知识蒸馏过程
for (size_t epoch = 0; epoch < 100; ++epoch) {
student_optimizer.zero_grad();
auto teacher_output = teacher_model.forward(input_features);
auto student_output = student_model.forward(input_features);
// 计算软标签损失
auto soft_labels = torch::softmax(teacher_output / 0.3, /*dim=*/1);
auto distillation_loss = torch::kl_div(torch::log_softmax(student_output / 0.3, /*dim=*/1), soft_labels);
distillation_loss *= (0.3 * 0.3);
// 计算硬标签损失
auto hard_labels = torch::one_hot(labels, 2).to(torch::kFloat32).to(device);
auto hard_loss = torch::nll_loss(student_output, labels);
// 组合损失
auto total_loss = hard_loss * 0.7 + distillation_loss * 0.3;
total_loss.backward();
student_optimizer.step();
if ((epoch + 1) % 10 == 0) {
std::cout << "Student Epoch [" << epoch + 1 << "/100], Loss: " << total_loss.item<float>() << std::endl;
}
}
// 评估学生模型的性能
auto predictions = student_model.forward(input_features).argmax(1);
auto accuracy = predictions.eq(labels).sum().item<float>() / labels.size(0);
std::cout << "Student Model Accuracy: " << accuracy << std::endl;
return 0;}
// 导入TensorFlow.js库
import * as tf from '@tensorflow/tfjs';
// 示例数据:随机生成100个样本,每个样本有10个特征,2个类别(0或1)
const numSamples = 100;
const inputDim = 10;
const outputDim = 2;
const inputFeatures = tf.randomNormal([numSamples, inputDim]);
const labels = tf.randomUniform([numSamples], 0, 2, 'int32');
// 创建教师模型
function createTeacherModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [inputDim], units: 50, activation: 'relu'}));
model.add(tf.layers.dense({units: outputDim}));
return model;
}
// 创建学生模型
function createStudentModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [inputDim], units: 20, activation: 'relu'}));
model.add(tf.layers.dense({units: outputDim}));
return model;
}
// 实例化教师模型和学生模型
const teacherModel = createTeacherModel(inputDim, outputDim);
const studentModel = createStudentModel(inputDim, outputDim);
// 编译模型
teacherModel.compile({
optimizer: 'sgd',
loss: tf.losses.sparseCategoricalCrossentropy,
metrics: ['accuracy']
});
studentModel.compile({
optimizer: 'sgd',
loss: tf.losses.sparseCategoricalCrossentropy,
metrics: ['accuracy']
});
// 训练教师模型
async function trainTeacherModel(model, inputs, labels, epochs) {
await model.fit(inputs, labels, {
epochs: epochs,
batchSize: 10,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(Teacher Epoch ${epoch + 1}/${epochs}, Loss: ${logs.loss.toFixed(4)}, Accuracy: ${logs.acc.toFixed(4)});
}
}
});
}
// 知识蒸馏过程
async function knowledgeDistillation(teacherModel, studentModel, inputs, labels, epochs, temperature, alpha) {
for (let epoch = 0; epoch < epochs; epoch++) {
// 获取教师模型的输出(软标签)
const teacherOutputs = teacherModel.predict(inputs).div(temperature);
const softLabels = tf.softmax(teacherOutputs, -1);
// 学生模型的预测
const studentOutputs = studentModel.predict(inputs);
// 计算交叉熵损失(使用软标签)
const distillationLoss = tf.losses.softmaxCrossEntropy(softLabels, studentOutputs.div(temperature)).mul(Math.pow(temperature, 2));
// 计算交叉熵损失(使用硬标签)
const hardLoss = tf.losses.sparseCategoricalCrossentropy(labels, studentOutputs);
// 组合损失
const totalLoss = distillationLoss.mul(alpha).add(hardLoss.mul(1 - alpha));
// 反向传播和优化
await studentModel.optimizer.minimize(() => totalLoss, () => studentModel.trainableWeights);
if ((epoch + 1) % 10 === 0) {
console.log(`Student Epoch ${epoch + 1}/${epochs}, Total Loss: ${totalLoss.dataSync()[0].toFixed(4)}`);
}
}}
// 测试学生模型的性能
async function evaluateStudentModel(model, inputs, labels) {
const evalResult = await model.evaluate(inputs, labels);
console.log(Student Model Accuracy: ${evalResult[1].dataSync()[0].toFixed(4)});
}
// 主函数
(async () => {
const numTeacherEpochs = 50;
const numStudentEpochs = 100;
const temperature = 3.0; // 温度参数,用于控制软标签的“软硬度”
const alpha = 0.7; // 软标签和硬标签的权重
// 训练教师模型
await trainTeacherModel(teacherModel, inputFeatures, labels, numTeacherEpochs);
// 知识蒸馏过程
await knowledgeDistillation(teacherModel, studentModel, inputFeatures, labels, numStudentEpochs, temperature, alpha);
// 测试学生模型的性能
await evaluateStudentModel(studentModel, inputFeatures, labels);})();
import * as tf from '@tensorflow/tfjs';
// 定义一个简单的神经网络作为教师模型
function createTeacherModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({ inputShape: [inputDim], units: 50, activation: 'relu' }));
model.add(tf.layers.dense({ units: outputDim, activation: 'softmax' }));
return model;
}
// 定义一个简单的神经网络作为学生模型
function createStudentModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({ inputShape: [inputDim], units: 20, activation: 'relu' }));
model.add(tf.layers.dense({ units: outputDim, activation: 'softmax' }));
return model;
}
// 创建数据集
const numSamples = 100;
const inputDim = 10;
const outputDim = 2;
const inputFeatures = tf.randomNormal([numSamples, inputDim]);
const labels = tf.randomUniform([numSamples], 0, 2, 'int32');
// 初始化模型、损失函数和优化器
const teacherModel = createTeacherModel(inputDim, outputDim);
const studentModel = createStudentModel(inputDim, outputDim);
teacherModel.compile({
optimizer: 'sgd',
loss: 'sparseCategoricalCrossentropy',
metrics: ['accuracy']
});
studentModel.compile({
optimizer: 'sgd',
loss: 'sparseCategoricalCrossentropy',
metrics: ['accuracy']
});
// 训练教师模型(这里我们假设教师模型已经预训练好了)
async function trainTeacherModel(model, inputs, labels, epochs) {
await model.fit(inputs, labels, {
epochs: epochs,
batchSize: 10,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(Teacher Epoch ${epoch + 1}/${epochs}, Loss: ${logs.loss.toFixed(4)}, Accuracy: ${logs.acc.toFixed(4)});
}
}
});
}
// 知识蒸馏过程
async function knowledgeDistillation(teacherModel, studentModel, inputs, labels, epochs, temperature, alpha) {
for (let epoch = 0; epoch < epochs; epoch++) {
// 获取教师模型的输出(软标签)
const teacherOutputs = teacherModel.predict(inputs).div(temperature);
const softLabels = tf.softmax(teacherOutputs, -1);
// 学生模型的预测
const studentOutputs = studentModel.predict(inputs);
// 计算硬标签损失
const hardLoss = tf.losses.sparseCategoricalCrossentropy(labels, studentOutputs);
// 计算软标签损失
const distillationLoss = tf.losses.softmaxCrossEntropy(softLabels, studentOutputs.div(temperature)).mul(Math.pow(temperature, 2));
// 组合损失
const totalLoss = hardLoss.mul(alpha).add(distillationLoss.mul(1 - alpha));
// 反向传播并更新权重
await studentModel.trainOnBatch(inputs, labels, { loss: () => totalLoss });
if ((epoch + 1) % 10 === 0) {
console.log(`Student Epoch ${epoch + 1}/${epochs}, Total Loss: ${totalLoss.dataSync()[0].toFixed(4)}`);
}
}
// 评估学生模型的性能
const evalResult = studentModel.evaluate(inputs, labels);
console.log(`Student Model Accuracy: ${evalResult[1].dataSync()[0].toFixed(4)}`);}
// 主函数
(async () => {
const numEpochsTeacher = 50;
const numEpochsStudent = 100;
const temperature = 3.0; // 温度参数,用于控制软标签的“软硬度”
const alpha = 0.7; // 硬标签损失和软标签损失的权重
// 训练教师模型
await trainTeacherModel(teacherModel, inputFeatures, labels, numEpochsTeacher);
// 冻结教师模型参数
teacherModel.trainable = false;
// 知识蒸馏过程
await knowledgeDistillation(teacherModel, studentModel, inputFeatures, labels, numEpochsStudent, temperature, alpha);})();
import * as tf from '@tensorflow/tfjs';
// 定义一个简单的神经网络作为教师模型
function createTeacherModel() {
const model = tf.sequential();
model.add(tf.layers.dense({ units: 50, activation: 'relu', inputShape: [10] }));
model.add(tf.layers.dense({ units: 2 }));
return model;
}
// 定义一个简单的神经网络作为学生模型
function createStudentModel() {
const model = tf.sequential();
model.add(tf.layers.dense({ units: 20, activation: 'relu', inputShape: [10] }));
model.add(tf.layers.dense({ units: 2 }));
return model;
}
// 创建数据集
const numSamples = 100;
const featureSize = 10;
const inputFeatures = tf.randomNormal([numSamples, featureSize]);
const labels = tf.randomUniform([numSamples], 0, 2, 'int32');
// 初始化模型、损失函数和优化器
const teacherModel = createTeacherModel();
const studentModel = createStudentModel();
const optimizer = tf.train.sgd(0.01);
// 训练教师模型(这里我们假设教师模型已经预训练好了)
async function trainTeacherModel(model, inputs, labels, epochs) {
for (let epoch = 0; epoch < epochs; epoch++) {
await model.fit(inputs, labels, {
batchSize: 10,
epochs: 1,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(Teacher Epoch ${epoch + 1}/${epochs}, Loss: ${logs.loss.toFixed(4)});
}
}
});
}
}
// 知识蒸馏过程
async function knowledgeDistillation(teacherModel, studentModel, inputs, labels, epochs, temperature, alpha) {
for (let epoch = 0; epoch < epochs; epoch++) {
const { value: studentOutputs } = tf.tidy(() => {
// 获取教师模型的输出(软标签)
const teacherOutputs = teacherModel.predict(inputs).div(temperature);
const softLabels = tf.softmax(teacherOutputs, -1);
// 学生模型的输出
const studentOutputs = studentModel.predict(inputs);
// 计算交叉熵损失(使用软标签)
const distillationLoss = tf.losses.softmaxCrossEntropy(softLabels, studentOutputs.div(temperature)).mul(Math.pow(temperature, 2));
// 计算交叉熵损失(使用硬标签)
const oneHotLabels = tf.oneHot(labels, 2);
const hardLoss = tf.losses.softmaxCrossEntropy(oneHotLabels, studentOutputs);
// 组合损失
const totalLoss = distillationLoss.mul(alpha).add(hardLoss.mul(1 - alpha));
// 反向传播和优化
optimizer.minimize(totalLoss, () => studentModel.weights.map(w => w.variable));
return studentOutputs;
});
if ((epoch + 1) % 10 === 0) {
const lossValue = studentOutputs.dataSync()[0];
console.log(`Student Epoch ${epoch + 1}/${epochs}, Total Loss: ${lossValue.toFixed(4)}`);
}
}}
// 测试学生模型的性能
async function evaluateStudentModel(model, inputs, labels) {
const predictions = model.predict(inputs).argMax(-1);
const accuracy = predictions.equal(labels).mean().dataSync()[0];
console.log(Student Model Accuracy: ${accuracy.toFixed(4)});
}
// 主函数
(async () => {
const numTeacherEpochs = 50;
const numStudentEpochs = 100;
const temperature = 3.0; // 温度参数,用于控制软标签的“软硬度”
const alpha = 0.7; // 软标签和硬标签的权重
// 训练教师模型
await trainTeacherModel(teacherModel, inputFeatures, labels, numTeacherEpochs);
// 冻结教师模型参数
teacherModel.trainable = false;
// 知识蒸馏过程
await knowledgeDistillation(teacherModel, studentModel, inputFeatures, labels, numStudentEpochs, temperature, alpha);
// 测试学生模型的性能
await evaluateStudentModel(studentModel, inputFeatures, labels);})();
// 导入TensorFlow.js库
import * as tf from '@tensorflow/tfjs';
// 示例数据:随机生成100个样本,每个样本有10个特征,2个类别(0或1)
const numSamples = 100;
const inputDim = 10;
const outputDim = 2;
const inputFeatures = tf.randomNormal([numSamples, inputDim]);
const labels = tf.randomUniform([numSamples], 0, 2, 'int32');
// 创建教师模型
function createTeacherModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [inputDim], units: 50, activation: 'relu'}));
model.add(tf.layers.dense({units: outputDim, activation: 'softmax'}));
return model;
}
// 创建学生模型
function createStudentModel(inputDim, outputDim) {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [inputDim], units: 20, activation: 'relu'}));
model.add(tf.layers.dense({units: outputDim, activation: 'softmax'}));
return model;
}
// 实例化教师模型和学生模型
const teacherModel = createTeacherModel(inputDim, outputDim);
const studentModel = createStudentModel(inputDim, outputDim);
// 编译模型
teacherModel.compile({
optimizer: 'sgd',
loss: 'sparseCategoricalCrossentropy',
metrics: ['accuracy']
});
studentModel.compile({
optimizer: 'sgd',
loss: 'sparseCategoricalCrossentropy',
metrics: ['accuracy']
});
// 训练教师模型
async function trainTeacherModel(model, inputs, labels, epochs) {
await model.fit(inputs, labels, {
epochs: epochs,
batchSize: 10,
callbacks: {
onEpochEnd: (epoch, logs) => {
console.log(Teacher Epoch ${epoch + 1}/${epochs}, Loss: ${logs.loss.toFixed(4)}, Accuracy: ${logs.acc.toFixed(4)});
}
}
});
}
// 训练学生模型
async function trainStudentModel(studentModel, teacherModel, inputs, labels, epochs, temperature, alpha) {
for (let epoch = 0; epoch < epochs; epoch++) {
// 获取教师模型的输出(软标签)
const teacherOutputs = teacherModel.predict(inputs).div(temperature);
const softLabels = tf.softmax(teacherOutputs, 1);
// 学生模型的预测
const studentOutputs = studentModel.predict(inputs);
// 计算硬标签损失
const hardLoss = tf.losses.sparseCategoricalCrossentropy(labels, studentOutputs);
// 计算软标签损失
const softLoss = tf.metrics.kullbackLeiblerDivergence(
tf.log(tf.div(studentOutputs.clone().add(1e-7), temperature)),
softLabels
).mul(temperature ** 2);
// 组合损失
const loss = hardLoss.mul(alpha).add(softLoss.mul(1 - alpha));
// 反向传播并更新权重
studentModel.optimizer.minimize(() => loss, studentModel.trainableWeights);
if ((epoch + 1) % 10 === 0) {
console.log(`Student Epoch ${epoch + 1}/${epochs}, Loss: ${loss.dataSync()[0].toFixed(4)}`);
}
}
// 评估学生模型的性能
const evalResult = studentModel.evaluate(inputs, labels);
console.log(`Student Model Accuracy: ${evalResult[1].dataSync()[0].toFixed(4)}`);}
// 主函数
(async () => {
const numEpochsTeacher = 50;
const numEpochsStudent = 100;
const temperature = 3.0; // 温度参数,用于控制软标签的“软硬度”
const alpha = 0.7; // 硬标签损失和软标签损失的权重
// 训练教师模型
await trainTeacherModel(teacherModel, inputFeatures, labels, numEpochsTeacher);
// 训练学生模型
await trainStudentModel(studentModel, teacherModel, inputFeatures, labels, numEpochsStudent, temperature, alpha);})();
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
public class DataGenerator {
public static DataSet generateData(int numSamples, int numFeatures, int numClasses) {
// 生成随机输入特征
INDArray features = Nd4j.randn(numSamples, numFeatures);
// 生成随机标签(0或1)
INDArray labels = Nd4j.zeros(numSamples, numClasses);
for (int i = 0; i < numSamples; i++) {
labels.putScalar(new int[]{i, Nd4j.getRandom().nextInt(numClasses)}, 1);
}
return new DataSet(features, labels);
}
}
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class ModelGenerator {
public static MultiLayerNetwork createModel(int inputSize, int outputSize) {
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.list()
.layer(new DenseLayer.Builder().nIn(inputSize).nOut(64).activation(Activation.RELU).build())
.layer(new DenseLayer.Builder().nIn(64).nOut(32).activation(Activation.RELU).build())
.layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX).nIn(32).nOut(outputSize).build())
.build();
return new MultiLayerNetwork(conf);
}
}
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.indexing.NDArrayIndex;
public class DistillationTrainer {
public static void main(String[] args) {
int numSamples = 100;
int numFeatures = 10;
int numClasses = 2;
int numEpochs = 100;
double temperature = 3.0;
// 生成数据
DataSet dataSet = DataGenerator.generateData(numSamples, numFeatures, numClasses);
// 创建教师模型和学生模型
MultiLayerNetwork teacherModel = ModelGenerator.createModel(numFeatures, numClasses);
MultiLayerNetwork studentModel = ModelGenerator.createModel(numFeatures, numClasses);
// 训练教师模型
teacherModel.fit(dataSet);
// 生成软标签
INDArray softLabels = teacherModel.output(dataSet.getFeatures());
softLabels = Nd4j.softmax(softLabels.div(temperature), 1);
// 训练学生模型
for (int epoch = 0; epoch < numEpochs; epoch++) {
studentModel.fit(dataSet);
INDArray studentOutputs = studentModel.output(dataSet.getFeatures());
INDArray loss = Nd4j.mean(Nd4j.crossEntropyBinary(studentOutputs, softLabels));
System.out.println("Epoch " + epoch + " Loss: " + loss);
}
}}
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.indexing.NDArrayIndex;
public class ModelEvaluator {
public static void evaluateModel(MultiLayerNetwork model, DataSet dataSet) {
Evaluation eval = new Evaluation();
INDArray output = model.output(dataSet.getFeatures());
INDArray labels = dataSet.getLabels();
eval.eval(labels, output);
System.out.println(eval.stats());
}
}
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
示例数据:随机生成100个样本,每个样本有10个特征,0或1的二分类标签
input_features = torch.randn(100, 10)
labels = torch.randint(0, 2, (100,))
创建PyTorch数据集和数据加载器
dataset = TensorDataset(input_features, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
定义一个简单的神经网络作为教师模型
class TeacherModel(nn.Module):
def init(self):
super(TeacherModel, self).init()
self.fc = nn.Linear(10, 2) # 假设输入特征维度为10,输出维度为2
def forward(self, x):
return self.fc(x)定义一个简单的神经网络作为学生模型
class StudentModel(nn.Module):
def init(self):
super(StudentModel, self).init()
self.fc = nn.Linear(10, 2) # 假设输入特征维度为10,输出维度为2
def forward(self, x):
return self.fc(x)初始化模型、损失函数和优化器
teacher_model = TeacherModel()
student_model = StudentModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(student_model.parameters(), lr=0.01)
训练教师模型(这里我们假设教师模型已经预训练好了)
teacher_model.train()
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = teacher_model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
生成软标签并训练学生模型
num_epochs = 100
temperature = 3.0 # 温度参数,用于控制软标签的“软硬度”
for epoch in range(num_epochs):
student_model.train()
total_loss = 0.0
for inputs, targets in dataloader:
optimizer.zero_grad()
获取教师模型的输出(软标签)
with torch.no_grad():
teacher_outputs = teacher_model(inputs) / temperature
soft_labels = torch.softmax(teacher_outputs, dim=1)
# 计算交叉熵损失,使用教师模型的输出作为目标
student_outputs = student_model(inputs) / temperature
loss = criterion(student_outputs, soft_labels) * (temperature ** 2)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss/len(dataloader):.4f}')测试学生模型的性能
student_model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in dataloader:
outputs = studentmodel(inputs)
, predicted = torch.max(outputs, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = correct / total
print(f'Accuracy of the student model on test data: {accuracy:.4f}')
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset
示例数据:随机生成100个样本,每个样本有10个特征,2个类别(0或1)
input_features = torch.randn(100, 10)
labels = torch.randint(0, 2, (100,))
创建PyTorch数据集
dataset = TensorDataset(input_features, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
class SimpleNN(nn.Module):
def init(self, input_dim, output_dim):
super(SimpleNN, self).init()
self.fc = nn.Linear(input_dim, output_dim)
def forward(x):
return self.fc(x)实例化教师模型和学生模型
teacher_model = SimpleNN(10, 2).cuda()
student_model = SimpleNN(10, 2).cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(teacher_model.parameters(), lr=0.01)
num_epochs = 100
for epoch in range(num_epochs):
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = teacher_model(inputs.cuda())
loss = criterier(outputs, targets.cuda())
loss.backward()
optimizer.update()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
with torch.no_grad():
soft_labels = teacher_model(input_features.cuda())[1].cpu()
student_optimizer = optim.SGD(student_model.parameters(), lr=0.01)
student_criterion = nn.KLDivLoss(reduction='batchmean')
for epoch in range(num_epochs):
student_model.train()
for inputs, targets in dataloader:
student_optimizer.zero_grad()
outputs = student_model(inputs.cuda())
loss = student_criterion(torch.log_softmax(outputs/temperature, dim=1), soft_labels)
loss.backward()
student_optimizer.update()
print(f'Student Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
student_model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in dataloader:
outputs = studentmodel(inputs.cuda())
, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets.cuda()).sum().item()
accuracy = correct / total
print(f'Student Model Accuracy: {accuracy:.4f}')
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
def create_dataset(input_features, labels):
"""Create a PyTorch dataset from numpy arrays."""
dataset = TensorDataset(torch.tensor(input_features, dtype=torch.float32),
torch.tensor(labels, dtype=torch.long))
return dataset
Example data
input_features = torch.randn(100, 10) # 100 samples, each with 10 features
labels = torch.randint(0, 2, (100,)) # Binary labels
Create the dataset and dataloader
dataset = create_dataset(input_features, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
Define simple neural networks for teacher and student models
class SimpleNN(nn.Module):
def init(self, input_dim, output_dim):
super(SimpleNN, self).init()
self.fc = nn.Linear(input_dim, output_dim)
def forward(x):
return self.fc(x)Instantiate teacher and student models
teacher_model = SimpleNN(10, 2)
student_model = SimpleNN(10, 2)
Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(student_model.parameters(), lr=0.01)
Training loop for knowledge distillation
num_epochs = 100
for epoch in range(num_epochs):
for inputs, targets in dataloader:
Get outputs from the teacher model (soft targets)
with torch.no_grad():
teacher_outputs = teacher_model(inputs)
# Calculate cross-entropy loss using soft targets
loss = criterion(student_model(inputs), teacher_outputs.argmax(dim=1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
定义一个简单的神经网络作为学生模型
class StudentModel(nn.Module):
def init(self):
super(StudentModel, self).init()
self.fc = nn.Linear(10, 2) # 假设输入特征维度为10,输出维度为2
def forward(self, x):
return self.fc(x)定义一个简单的神经网络作为教师模型
class TeacherModel(nn.Module):
def init(self):
super(TeacherModel, self).init()
self.fc = nn.Linear(10, 2) # 假设输入特征维度为10,输出维度为2
def forward(self, x):
return self.fc(x)创建数据集
inputs = torch.randn(100, 10) # 随机生成100个样本,每个样本有10个特征
labels = torch.randint(0, 2, (100,)) # 随机生成标签
dataset = TensorDataset(inputs, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
初始化模型、损失函数和优化器
teacher_model = TeacherModel()
student_model = StudentModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(student_model.parameters(), lr=0.01)
训练学生模型
num_epochs = 100
for epoch in range(num_epochs):
student_model.train()
teacher_model.eval()
for inputs, labels in dataloader:
optimizer.zero_grad()
获取教师模型的输出(软标签)
with torch.no_grad():
teacher_outputs = teacher_model(inputs)
# 计算交叉熵损失,使用教师模型的输出作为目标
loss = criterion(student_model(inputs), teacher_outputs.argmax(dim=1))
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')- 预训练大型模型:首先使用大规模数据对一个大型模型进行预训练,使其学习到丰富的特征表示。
- 生成软标签:利用大型模型的输出(即概率分布)作为软标签,这些软标签包含了更多的信息和细节,帮助小型模型更好地学习大模型的知识。
- 训练小型模型:使用软标签作为目标,对小型模型进行训练,使其在保持较低参数量的同时,尽可能接近大型模型的性能。
- 调整温度参数:通过调整蒸馏过程中的温度参数,可以控制软标签的“软硬度”,从而平衡训练速度、稳定性和最终性能。
- 降低模型复杂度:通过压缩模型,减少参数数量和计算开销,使得模型更易于部署到资源受限的环境中。
- 提高推理速度:小型模型具有更少的参数和更简单的结构,因此在推理过程中可以更快地得到结果。
- 减少存储空间需求:小型模型占用的存储空间更小,便于在设备上部署。
知识蒸馏在多个领域中得到了广泛应用,包括计算机视觉、自然语言处理和边缘计算等。 此外,知识蒸馏还可以与其他技术结合使用,如量化和权重剪枝,进一步优化模型的性能和效率。
五行脉象数据化中医健康管理星轮双驱系统中的AI大模型星轮算法模型的蒸馏技术,通过知识蒸馏可以有效地将大型预训练模型的知识迁移到小型模型中,从而实现高效的知识传递和模型压缩,提升系统的性能和应用范围。
五行脉象数据化在中医健康管理中的具体应用和效果主要体现在以下几个方面:
-
精准诊断与个性化治疗:
- 通过五行理论结合现代科技,如AI和大数据技术,可以实现对脉象的精准分析和诊断。 例如,太极五行脉诊方法通过量化、质化、标准化、精准化、数据化等手段,使脉诊有数据可依,有理义可循,从而提高诊断的可靠性和可操作性。
- 五行数据分析方法通过收集患者的面色、声音、舌苔、脉象等相关数据,并结合五行理论进行分析,帮助医师更准确地了解患者的病情,从而制定更有针对性的治疗方案。
-
健康管理与预防:
- 中医数字健康管理通过智能穿戴设备实时监测健康参数,并将数据上传至云端,形成完整、全面的健康档案。 医生和顾问可以根据这些数据,结合中医理论和经验,制定出最佳的健康管理方案,包括饮食调理、药膳食疗、体育锻炼、中药养生等。
- 基于五行理论的健康管理软件可以为用户提供五行人的分类及对应的保健方案,包括芳疗、茶饮、膳食等,帮助用户更好地管理自己的健康。
-
提高诊疗效率与准确性:
- AI赋能的中医脉象采集与分析系统,如依脉中医四诊智能诊断系统,通过无级气动加压技术和高精度传感器,精准模拟传统切诊,高效采集脉象信息,实现数据标准化。 系统能够智能辨析单脉与相兼脉类别,生成脉象图谱,辅助科学诊断。
- 市场中的一些智能脉诊设备正在开发中,未来可以应用在诊所与家庭场景中,一方面给中医师提供诊疗辅助建议; 另一方面,用户也可以在家庭中使用智能脉诊设备记录自身的身体变化情况,了解服药后的效果并进行健康管理。
-
市场推广与招商:
- 镜心悟道AI易经智能“大脑”五行脉象团队结合中医五行理论与现代科技,提供全方位的健康管理服务,并利用SEO和招商矩阵模型提升品牌知名度,吸引潜在客户。
- 该团队运用中医五行理论,结合AI技术,为客户提供个性化的健康管理和招商服务,具备中医五行诊断、个性化治疗方案制定、AI辅助决策、市场推广与招商等核心能力。
-
用户体验与市场前景:
- 数字化中医脉象诊断系统不仅提升了中医诊断效率与准确度,还让现代科技辅助下的用户更好地认识自我、呵护健康。
- 基于移动通信终端的数字化中医脉象诊断系统适用于中医脉诊和中医教学,推广前景广阔,尤其适用于中老年人的家庭医护监测。
五行脉象数据化在中医健康管理中的应用不仅提高了诊断的精准度和治疗的个性化水平,还通过现代科技手段提升了用户体验和市场推广效果。
星轮算法模型在AI大模型中的具体实现和优化策略是什么?
根据提供的信息,无法直接回答关于星轮算法模型在AI大模型中的具体实现和优化策略的问题。 我搜索到的资料主要涉及聆思科技的语音交互解决方案和科大讯飞的“星火”认知大模型,但没有具体提到“星轮”算法模型。
然而,可以从我搜索到的资料中提取一些与大模型相关的技术和优化策略:
-
聆思科技的语音交互解决方案:
- 芯片加速:聆思科技基于CSK6系芯片,实现了语音降噪、识别等关键环节的高效处理,端侧响应速度达到≤200ms 。
- 云端技术:云端ASR技术结合VAD算法,提升了识别准确率至98%,并实现了智能决策调用 。
- 流式文本语音合成技术:使语音全链路响应时间缩短至1.5秒,显著提升了用户体验 。
- 大模型接口:聆思语音开发套件已升级,成功接入星火V3.0接口,支持基于最新大模型的产品开发,增强了复杂语义理解、逻辑推理、多轮对话等方面的能力 。
-
科大讯飞的“星火”认知大模型:
- 多场景应用:星火大模型具备与AI学习机、讯飞听见、智能办公、智能座舱和数字员工等多场景结合的能力 。
- 实时问答和多轮对话:计划在6月9日前开启实时问答,升级多轮对话能力 。
- 代码能力和多模态交互:计划在8月15日前提升代码能力和多模态交互能力 。
- 对标ChatGPT:计划在10月24日前,使星火大模型在中文能力上超过ChatGPT,在英文能力上与ChatGPT相当 。
虽然这些信息没有直接提到“星轮”算法模型,但它们展示了大模型在语音识别、多模态交互、实时问答和多轮对话等方面的技术实现和优化策略。
知识蒸馏技术在中医健康管理领域的成功案例有哪些?
根据提供的信息,无法回答关于知识蒸馏技术在中医健康管理领域的成功案例的具体问题。 我搜索到的资料主要集中在知识蒸馏技术在医疗领域的应用,包括医疗影像分析、药物推荐、生物医学实例分割等方面,但没有具体提到中医健康管理领域的成功案例。
然而,可以参考一些相关的信息来推测知识蒸馏技术在中医健康管理领域可能的应用:
-
中医药知识的传播与应用:通过知识蒸馏技术,可以将复杂的中医药知识和临床经验从大型教师模型转移到更小、更高效的学生模型中,有助于在有限的计算资源下提供快速、准确的中医药诊断和治疗建议,促进中医药知识的更广泛传播和应用。
-
个性化医疗方案的制定:知识蒸馏还可以用于个性化医疗方案的制定。 通过“蒸馏”大型的个性化治疗模型,可以创建出更易于部署和使用的模型,根据每个患者的特定情况,提供定制化的治疗建议,提高治疗效果和患者满意度。
-
医疗知识图谱构建:在构建医疗知识图谱时,知识蒸馏技术可以帮助从大量的文献、病例和研究中提取关键知识,构建出更精简、更易于理解和查询的知识图谱,为医疗研究和临床实践提供支持。
如何评估知识蒸馏技术在提升中医健康管理系统性能方面的有效性?
根据提供的信息,无法直接评估知识蒸馏技术在提升中医健康管理系统性能方面的有效性。 我搜索到的资料主要集中在知识蒸馏技术在其他领域的应用和效果,如医学图像分割、药物推荐、医疗诊断等,但没有具体提到中医健康管理系统。
然而,我们可以从我搜索到的资料中提取一些通用的信息,来推测知识蒸馏技术在中医健康管理系统中的潜在应用和效果:
-
知识蒸馏的基本原理:
知识蒸馏是一种模型压缩技术,通过从大型复杂模型(教师模型)中提取知识,并将其传递给较小的模型(学生模型),从而在减小模型尺寸的同时保持性能。 这种方法可以应用于任何需要模型压缩和性能提升的场景。 -
医疗领域的应用:
知识蒸馏在医疗领域的应用已经取得了显著的成果。 例如,在医学图像分割中,通过三重增强蒸馏提高了知识多样性、准确性和稳定性; 在药物推荐中,通过知识蒸馏将大型语言模型(LLMs)的能力转移到小型模型,提高了药物推荐的准确性和效率; 在医疗诊断中,知识蒸馏可以帮助模型快速学习新的医学数据,提供更准确的诊断结果。 -
中医健康管理系统的特点:
中医健康管理系统通常涉及大量的医疗数据和复杂的诊断逻辑。 知识蒸馏技术可以用于以下几个方面:- 模型压缩:通过知识蒸馏,可以将复杂的中医诊断模型压缩成更小的模型,从而提高系统的响应速度和资源利用率。
- 知识迁移:中医健康管理系统需要不断更新和学习新的医学知识。 知识蒸馏可以帮助系统快速吸收新知识,提高诊断的准确性和及时性。
- 性能提升:通过知识蒸馏,可以提高中医健康管理系统在处理复杂医疗数据时的性能,确保系统在高负载下的稳定性和可靠性。
-
潜在的挑战:
- 数据质量和多样性:中医健康管理系统需要大量的高质量和多样化的医疗数据。 如果数据不足或质量不高,知识蒸馏的效果可能会受到影响。
- 模型复杂性:中医诊断涉及复杂的逻辑和规则,模型的复杂性较高。 如何有效地从复杂模型中提取知识并传递给学生模型是一个挑战。
- 评估方法:需要开发合适的评估方法来确保知识蒸馏的效果。 避免过度拟合和确保评估结果的解释性是关键。
综上所述,虽然我搜索到的资料没有直接涉及中医健康管理系统,但知识蒸馏技术在其他医疗领域的成功应用表明,它在提升中医健康管理系统性能方面具有很大的潜力。
知识蒸馏与其他模型压缩技术(如量化和权重剪枝)结合使用的最新研究进展是什么?
目前,知识蒸馏与其他模型压缩技术(如量化和权重剪枝)结合使用的最新研究进展主要集中在以下几个方面:
-
多模态模型压缩:随着多模态数据(如图像、文本和语音等)的普及,研究者正在探索如何将不同的模型压缩技术应用于多模态数据,以实现更高的压缩率和性能。 例如,结合知识蒸馏、剪枝和量化技术,可以显著提高多模态模型的压缩效果和运行效率。
-
自蒸馏方法
蒸馏技术的核心包括以下几个方面: -
知识重构:大模型在处理问题时会形成复杂的神经网络连接,蒸馏过程通过分析这些连接,找出最关键的路径,并通过数学优化简化为更精简的结构。
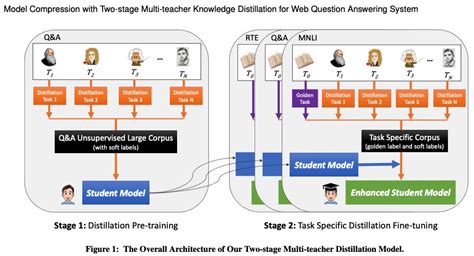
-
概率分布学习:蒸馏不仅关注答案的复制,还捕捉大模型在不同选项间的权重分配,使小模型能够学习到这种细腻的判断能力。
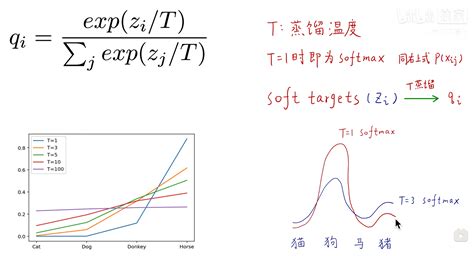
-
表征空间压缩:大模型的知识分布在高维空间中,蒸馏通过数学降维找到更高效的表达方式,大幅减少计算复杂度。
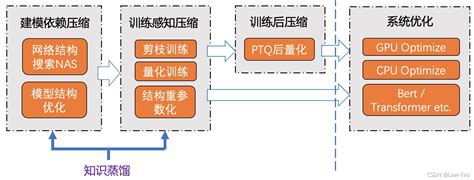
-
教师-学生模型架构:蒸馏通常采用教师-学生模型架构,其中大型模型作为教师,小型模型作为学生。学生模型通过模仿教师模型的输出进行训练,从而学习到教师模型的知识。
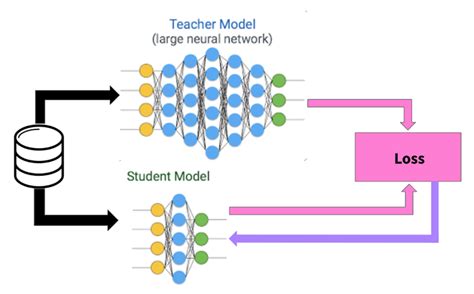
-
多任务与跨模态蒸馏:蒸馏技术已经从单一任务的蒸馏发展到多任务蒸馏、跨模态蒸馏和动态蒸馏,以适应不同场景的需求。
-
实际应用:蒸馏技术广泛应用于自然语言处理、计算机视觉、语音识别等领域,特别是在大语言模型(如BERT、GPT等)的压缩和加速方面取得了显著成功。此外,蒸馏技术还被应用于边缘设备上的AI计算,使大模型能够在资源有限的环境中运行。
-
未来趋势:未来蒸馏技术将更加自适应,支持多模态蒸馏、联邦蒸馏和集成蒸馏,以应对不同任务和数据特性,实现更高效、准确的模型部署。
尽管蒸馏技术带来了许多优势,但也面临一些挑战,如知识表示与传递、模型对齐、性能效率平衡和泛化能力保持等问题。然而,随着技术的不断进步,这些挑战有望逐步得到解决。
蒸馏技术在自然语言处理(NLP)领域的最新应用和案例研究主要集中在以下几个方面:
-
模型压缩与加速:
蒸馏技术通过将大型预训练模型的知识传递给较小模型,实现了模型规模的减小,同时保持或提升性能。例如,Distillation with Soft Targets和Knowledge Distillation with Gaussian Teachers等文献提出了新的蒸馏方法,以提高模型的知识迁移效果。此外,模块化知识蒸馏技术也被应用于端到端文本转语音合成,显著降低了模型尺寸至5.23M参数,加速了处理速度,同时保持了良好的声音自然性。 -
跨语言和跨领域模型迁移:
一些研究探索了使用蒸馏方法进行跨语言和跨领域的模型迁移。这有助于在不同语言和领域之间共享知识,提高模型的泛化能力。 -
多教师BERT模型蒸馏:
多教师BERT模型蒸馏研究探讨了如何利用多个教师模型来优化BERT及其变体(如XLNet、ALBERT、TinyBERT等)的性能。这种方法通过结合多个教师模型的知识,提高了模型在自然语言理解任务中的表现。 -
实际应用案例:
- 智能客服:深度学习模型通过蒸馏技术提高了实时性和响应速度,能够理解用户意图并生成准确回复。
- 广告推荐和舆情监测:通过分析用户问题、兴趣和行为,提供精准服务和风险预警。
- 文本分类:蒸馏技术在文本分类任务中表现出色,能够高效地将大模型的知识传递给小模型,实现高效且性能优异的应用。
-
未来发展趋势:
未来,蒸馏技术有望扩展到更多深度学习任务,并与知识蒸馏、网络剪枝、量化和加速推理等技术结合,进一步提升模型的效率和性能。此外,自适应蒸馏、联邦蒸馏和集成蒸馏等新技术也将推动蒸馏技术在更广泛领域的应用。
蒸馏技术在自然语言处理领域的最新应用和案例研究展示了其在模型压缩、加速、跨语言和跨领域迁移以及实际应用中的巨大潜力。
如何解决AI大模型蒸馏过程中的知识表示与传递问题?
在AI大模型蒸馏过程中,知识表示与传递问题的解决方法可以从以下几个方面进行详细探讨:
-
软目标与温度参数调整:
知识蒸馏的核心思想之一是使用教师模型的软目标(即概率分布)而不是硬标签(即类别标签)来训练学生模型。这种方法可以提供更丰富的信息,帮助学生模型学习到更细微的类别差异。通过调整温度参数,可以控制软目标的“软度”,从而更好地传递教师模型的知识。 -
损失函数的设计:
在知识蒸馏中,通常会结合蒸馏损失和学生损失来优化模型。蒸馏损失通常包括Kullback-Leibler散度(KL散度),用于衡量学生模型输出与教师模型输出之间的差异。此外,还可以引入其他损失项,如分类损失,以确保学生模型在特定任务上的表现。 -
特征蒸馏:
特征蒸馏是指将教师模型的内部特征传递给学生模型。这可以通过在训练过程中提取教师模型的中间层特征,并将这些特征作为额外的监督信息传递给学生模型来实现。这种方法有助于学生模型更好地理解教师模型的内部表示。 -
集群级蒸馏与实例级蒸馏:
集群级蒸馏(Cluster-level Distillation)和实例级蒸馏(Instance-level Distillation)是两种有效的蒸馏方法。集群级蒸馏通过优化softmax分类损失和Kullback-Leibler散度,实现集群级蒸馏损失,使用教师模型的图像和文本嵌入来监督学生模型的文本和图像嵌入。实例级蒸馏则关注于单个实例的细节,通过更精细的对齐机制提高蒸馏效果。 -
伪标签生成:
在知识蒸馏过程中,通常需要生成伪标签来训练学生模型。伪标签可以通过教师模型在特定任务上的输出生成。这种方法不仅可以减少对标注数据的依赖,还可以提高学生模型的泛化能力。 -
动态学习率调整:
动态学习率调整可以根据训练过程中模型的性能变化,动态调整学习率,以优化模型的收敛速度与泛化能力。这种方法有助于在蒸馏过程中保持模型的稳定性和高效性。 -
多模态学习:
在多模态学习中,知识蒸馏可以通过将不同模态的信息融合,实现跨模态的学习和应用。这种方法不仅提高了模型的性能,还增强了其泛化能力。 -
迁移学习结合:
知识蒸馏可以与迁移学习结合使用,通过迁移学习获取源域模型的知识,然后通过知识蒸馏将这些知识传递给目标域模型。这种方法在多域数据分布不一致的情况下特别有效。
AI大模型蒸馏技术中模型对齐的最佳实践和方法有哪些?
在AI大模型蒸馏技术中,模型对齐的最佳实践和方法主要包括以下几种:
-
迭代蒸馏和扩增(Iterated Distillation and Amplification, IDA):
这种方法由Paul Christiano等人提出,旨在解决人类难以在复杂任务上评测AI代理的问题。初始时,人类将知识蒸馏给一个比自己弱的AI代理,这个过程称为蒸馏(Distillation)。接着,人类可以使用蒸馏的AI代理辅助自己,得到扩增版的新代理,这个过程称为扩增(Amplification)。通过不断迭代蒸馏和扩增,AI代理的能力和对齐能力不断增强。 -
直接偏好优化(Distilled Direct Preference Optimization, dDPO):
这种方法利用教师模型集合的人工智能反馈(AIF)作为偏好数据,并应用蒸馏直接偏好优化作为学习目标。通过这种方法,可以完全对齐小型开源大语言模型(LLMs),使其更好地对齐用户意图。例如,Zephyr-7B模型就是通过dDPO方法训练的,证明了偏好学习在提升模型对齐性方面的重要性。 -
数据集蒸馏中的优先对齐:
在数据集蒸馏中,通过优先考虑对齐的方法来提升模型性能。具体步骤包括信息提取和信息嵌入。在信息提取阶段,采用数据选择策略,让不同的IPC从具有预期难度级别的数据子集中提取模式。在信息嵌入阶段,遮挡浅层参数,避免过度注入低级信息。这种方法已在多个知名基准上实现了新的SOTA。 -
模型融合技术:
大模型融合方法包括集成学习、多任务学习以及蒸馏学习等。这些方法在不同层面上实现了多个模型的协同工作,从而提升了整体性能。例如,蒸馏学习通过将一个庞大而复杂的模型(教师模型)的知识迁移到一个小巧且高效的模型(学生模型)上,显著降低了模型部署和推理的计算开销。 -
知识蒸馏:
知识蒸馏是一种常见的模型优化方法,通过将大型模型的知识传递给小型模型,使小型模型能够继承大型模型的能力。这种方法不仅减少了模型的计算复杂度和存储开销,还能提高模型的计算效率和性能。 -
动态加载:
动态加载是根据任务需求,适时加载大模型的部分或全部权重到小模型中,实现灵活、高效的模型融合。这种方法在不同应用场景中表现出色。
在边缘设备上应用AI大模型蒸馏技术的挑战和解决方案是什么?
在边缘设备上应用AI大模型蒸馏技术面临的挑战和解决方案可以从多个方面进行分析和讨论。
挑战
-
硬件需求:
- 大模型的运算能力依赖于强大的GPU、海量内存和算力。如果模型被蒸馏至更小规模,所需的芯片性能将极高,且价格昂贵,全球范围内可能尚未出现基于Transformer架构的SOC芯片。
- 即便有高性能芯片,其成本也难以支撑终端售价仅几百元的智能音箱等设备。
-
成本问题:
- 高性能芯片的成本较高,难以在资源有限的边缘设备上实现大规模部署。
-
硬件性能限制:
- 真正满足端侧计算需求的硬件只能是手机,因为手机在内存、成本和算力上都能承载高端芯片。
-
资源限制:
- 边缘设备通常资源有限,难以运行大型的LLM。
-
数据隐私:
- 边缘AI需要在设备端处理数据,可能会引发隐私问题。
-
模型泛化:
- 边缘设备通常面临数据多样性的挑战,需要模型具有更好的泛化能力。
解决方案
-
模型压缩技术:
- 采用量化、剪枝、知识蒸馏和低秩分解等模型压缩技术,提升计算效率。
- 通过权重裁剪、量化和知识蒸馏等方法减小模型大小和计算复杂度。
-
知识蒸馏:
- 知识蒸馏技术通过从大型模型向小型模型转移知识,确保小型模型能够复制大型模型的性能,同时减小模型大小。
- 谷歌DeepMind开源的Gemma 2模型通过引入知识蒸馏技术,大幅减少了模型计算资源需求,实现了卓越性能。
-
硬件在线微调学习能力:
- 边缘设备具备在线微调学习能力,通过能力蒸馏研发的轻量化模型和MoE大模型,边缘应用性能普遍优于同等参数模型。
-
多智体系统进化:
- AI与新基建相辅相成,形成正向循环,多智体系统由多个智能体构成,智能单体具备感知、存、算、通信能力。
-
端侧动态与云端协同:
- 终端模型与云端模型协同服务,存、算、网同步升级,AI重塑操作系统是释放大模型潜力的关键。
-
智能算力加速下放:
- 国产AI芯片积极生态适配,边缘大模型与端侧AI应用态势趋显。
-
技术标准化与产业化瓶颈:
- 研究面向终端设备的轻量化模型部署方案,通过模型拆分、知识蒸馏等技术,实现大模型在边缘设备上的低成本高效应用。
-
工具和资源推荐:
- 推荐使用TensorFlow Model Optimization Toolkit、PyTorch Model Optimization Toolkit和ONNX等工具来实现模型压缩和优化。
针对多模态蒸馏、联邦蒸馏和集成蒸馏的最新研究进展有哪些?
针对多模态蒸馏、联邦蒸馏和集成蒸馏的最新研究进展如下:
多模态蒸馏
- 模块级自适应蒸馏:针对多模态基础模型的蒸馏,提出了一种自适应蒸馏方法。该方法通过跟踪每个模块对学生模型性能的贡献,选择更应被蒸馏的模块,以优化模型大小。具体采用改良的Thompson采样算法OPTIMA,解决了模型更新导致的模块贡献非稳定性问题。
- 多模态融合的知识蒸馏:结合注意力机制、图网络等技术,有效融合多模态信息,提升小模型性能。研究方向包括跨模态知识蒸馏、模态特定与模态共享的知识蒸馏、自适应多模态知识蒸馏以及多模态自监督学习与知识蒸馏的结合。
- 多视角蒸馏与多模态融合:在少样本动作识别中,提出了基于多模态融合的多视角蒸馏方法,通过结合不同视角的信息,提高了模型在少样本情况下的识别能力。
联邦蒸馏
- 异质联邦学习蒸馏(DFRD) :针对异质联邦学习中数据和模型异质性带来的挑战,提出了一种数据免费知识蒸馏方法。该方法利用服务器上的条件生成器近似客户端上传模型的训练空间,并维护服务器上的指数移动平均生成器副本,以应对分布式通信轮次中模型分布变化导致的灾难性遗忘问题,实现联邦学习中的鲁棒性蒸馏。
集成蒸馏
目前我搜索到的资料中没有直接提到集成蒸馏的具体研究进展。然而,集成蒸馏通常涉及将多个模型的预测结果进行融合,以提高整体性能。这方面的研究可能涉及模型集成技术的改进和优化,但具体细节需要进一步的文献支持。
综上所述,多模态蒸馏和联邦蒸馏的研究进展主要集中在提高模型性能、减少偏见、增强可解释性和应对数据异质性等方面。
<内系统> 镜心悟道AI易经智能“大脑”</内系统>中医健康管理星轮算法模型(TCM-HMSWM)详解- <五行轮系统>:五行(金、木、水、火、土)</五行轮系统>- <9ED轮齿>:9ED可能代表一个九层的演化算法或九维的评估系统,每个层级或维度对应五行中的一个元素。通过这种多维度的分析,系统能够更精确地评估和管理健康状态。</9ED轮齿>- <六十四复合卦延伸外系统>:在易经中,六十四卦是由八个基本卦(八卦)两两组合而成,代表了自然界和人类社会的各种现象和状态。在星轮模型中,六十四卦的延伸意味着对健康状态的全面分析和预测,结合五行理论,进一步细化健康管理的维度。</六十四复合卦延伸外系统>
中医健康管理星轮模型(Traditional Chinese Medicine Health Management Starwheel Model, TCM-HMSWM)是一个结合了传统中医理论、易经智慧与现代人工智能技术的综合性健康管理系统。以下是对该模型核心概念和架构的详细解释:
1. 镜心悟道五行系统9ED
- 五行系统:五行(金、木、水、火、土)是中国传统文化的核心理论之一,用于描述自然界和人体内部的相互关系。在中医中,五行理论被广泛应用于解释人体的生理功能、病理变化以及疾病的诊断与治疗。
- 9ED:9ED可能代表一个九层的演化算法或九维的评估系统,每个层级或维度对应五行中的一个元素。通过这种多维度的分析,系统能够更精确地评估和管理健康状态。
2. 中医健康管理星轮模型
- 星轮模型:星轮模型象征着永恒的循环和动态平衡,这与中医强调的人体内外环境平衡的理念相契合。星轮模型通过循环和动态变化来描述健康管理的全面性。
- 六十四复合卦延伸:在易经中,六十四卦是由八个基本卦(八卦)两两组合而成,代表了自然界和人类社会的各种现象和状态。在星轮模型中,六十四卦的延伸意味着对健康状态的全面分析和预测,结合五行理论,进一步细化健康管理的维度。
3. 镜心悟道AI易经智能大脑
- AI易经智能大脑:这是镜心悟道公司的核心技术,结合了人工智能技术与易经智慧,用于提供个性化的中医健康管理服务。该系统能够分析用户的健康状况,生成个性化的健康建议和治疗方案。
- 双驱动五星齿轮:
- 双驱动:可能指系统有两个主要的驱动力或工作流程,协同工作以提高系统的效能。
- 五星齿轮:五星代表五行,齿轮象征动力传输和机制运作。五星齿轮体现了五行理论在系统中的应用,以及五行元素如何相互作用来推动健康管理过程。
4. 多元多维矩阵理论的应用
镜心悟道AI易经智能大脑通过多元多维矩阵理论实现健康状态的动态评估和管理,具体应用包括:
- 全面健康评估:通过SNLP招商矩阵模型(MHE-AIIB-SNLP-BIMM+SEO),系统综合考虑多个维度的数据和信息,提供全面的健康状况分析。
- 个性化解决方案:根据用户的健康信息生成定制化的健康管理方案,满足个性化需求。
- 多智能体系统架构:利用多智能体系统(Multi-Agent System)提升系统的鲁棒性和适应性,确保评估结果的准确性和可靠性。
- 大数据分析:结合中医智慧与现代科技,通过大数据分析提供科学、个性化的健康管理服务。
- 在线与线下服务结合:适用于在线咨询、线下健康管理及企业健康管理等多个场景,提供综合服务。
- 效果评估与持续改进:通过设定效果评估节点,持续优化健康管理方案,确保其长期有效性。
5. 镜心悟道五行系统与六十四卦结合的实际应用
-
中医诊断与治疗:
- 医案镜心悟道日主八字类:通过患者的生辰八字(BaZi),结合五行相生相克的逻辑,辅助中医诊断和治疗。
- 六十四卦与《伤寒论》的应用:六十四卦与中医经典《伤寒论》紧密结合,帮助医生理解疾病的阴阳变化,进行精准诊断和治疗。
-
自然语言处理与智能系统:
- 镜心悟道NLP系统:结合易经智慧与AI技术,支持五行相生相克逻辑和八卦六十四卦演算逻辑,提升系统对中医专业术语的理解和处理能力。
-
生活决策与哲学思考:
- 六十四卦五行属性解析:通过理解六十四卦的五行属性,将易经哲学应用于生活决策,帮助用户保持内心的平衡和谐。
-
预测学与数术之易:
- 六十四卦与六十甲子的联系:结合六十四卦与六十甲子,进行更精确的健康预测和分析。
6. 智能体协作框架(MACF)的应用
智能体协作框架(Multi-Agent Collaboration Framework, MACF)在镜心悟道AI易经智能大脑中的作用包括:
- 多智能体协作:实现智能体间的高效协作与竞争,特别是在复杂的任务分配和策略选择中。
- 智能合约与学习反馈:通过智能合约和学习反馈机制,提升系统在不同任务和环境中的适应性和性能。
- 人机交互:协调人类用户与智能系统的互动,提升用户体验和系统整体性能。
7. 星轮减速器模型的映射与类比
星轮减速器模型是一种高效的机械传动装置,其核心特征是通过行星轮的自转和公转实现减速和扭矩放大。将其映射到中医健康管理星轮模型中:
- 行星轮:象征五行元素,通过相互作用推动健康管理的动态平衡。
- 减速与放大:类比于健康管理中对疾病风险的“减速”和对健康状态的“放大”。
- 模块化设计:类似于星轮减速器的模块化核心单元,中医健康管理星轮模型也具备灵活性和可扩展性。
总结
中医健康管理星轮模型(TCM-HMSWM)通过结合传统中医理论、易经智慧与现代AI技术,实现了健康管理的智能化和个性化。其核心架构包括五行系统9ED、六十四复合卦延伸、AI易经智能大脑和双驱动五星齿轮,通过多元多维矩阵理论和智能体协作框架,为用户提供精准的健康评估和管理服务。这一模型不仅体现了传统智慧的现代应用,也为未来健康管理技术的发展提供了新的方向。
中医健康管理星轮模型(TCM-HMSWM)是一个结合了传统中医理论、易经智慧与现代人工智能技术的综合性健康管理系统。 以下是对该模型核心概念和架构的详细解释:
1. 镜心悟道五行系统9ED
- 五行系统:五行(金、木、水、火、土)是中国传统文化的核心理论之一,用于描述自然界和人体内部的相互关系。 在中医中,五行理论被广泛应用于解释人体的生理功能、病理变化以及疾病的诊断与治疗。
- 9ED:9ED可能代表一个九层的演化算法或九维的评估系统,每个层级或维度对应五行中的一个元素。 通过这种多维度的分析,系统能够更精确地评估和管理健康状态。
2. 中医健康管理星轮模型
- 星轮模型:星轮模型象征着永恒的循环和动态平衡,这与中医强调的人体内外环境平衡的理念相契合。 星轮模型通过循环和动态变化来描述健康管理的全面性。
- 六十四复合卦延伸:在易经中,六十四卦是由八个基本卦(八卦)两两组合而成,代表了自然界和人类社会的各种现象和状态。 在星轮模型中,六十四卦的延伸意味着对健康状态的全面分析和预测,结合五行理论,进一步细化健康管理的维度。
3. 镜心悟道AI易经智能大脑
- AI易经智能大脑:这是镜心悟道公司的核心技术,结合了人工智能技术与易经智慧,用于提供个性化的中医健康管理服务。 该系统能够分析用户的健康状况,生成个性化的健康建议和治疗方案。
- 双驱动五星齿轮:
- 双驱动:可能指系统有两个主要的驱动力或工作流程,协同工作以提高系统的效能。
- 五星齿轮:五星代表五行,齿轮象征动力传输和机制运作。 五星齿轮体现了五行理论在系统中的应用,以及五行元素如何相互作用来推动健康管理过程。
4. 多元多维矩阵理论的应用
镜心悟道AI易经智能大脑通过多元多维矩阵理论实现健康状态的动态评估和管理,具体应用包括:
- 全面健康评估:通过SNLP招商矩阵模型(MHE-AIIB-SNLP-BIMM+SEO),系统综合考虑多个维度的数据和信息,提供全面的健康状况分析。
- 个性化解决方案:根据用户的健康信息生成定制化的健康管理方案,满足个性化需求。
- 多智能体系统架构:利用多智能体系统(Multi-Agent System)提升系统的鲁棒性和适应性,确保评估结果的准确性和可靠性。
- 大数据分析:结合中医智慧与现代科技,通过大数据分析提供科学、个性化的健康管理服务。
- 在线与线下服务结合:适用于在线咨询、线下健康管理及企业健康管理等多个场景,提供综合服务。
- 效果评估与持续改进:通过设定效果评估节点,持续优化健康管理方案,确保其长期有效性。
5. 镜心悟道五行系统与六十四卦结合的实际应用
- 中医诊断与治疗:
- 医案镜心悟道日主八字类:通过患者的生辰八字(BaZi),结合五行相生相克的逻辑,辅助中医诊断和治疗。
- 六十四卦与《伤寒论》的应用:六十四卦与中医经典《伤寒论》紧密结合,帮助医生理解疾病的阴阳变化,进行精准诊断和治疗。
-
自然语言处理与智能系统:
- 镜心悟道NLP系统:结合易经智慧与AI技术,支持五行相生相克逻辑和八卦六十四卦演算逻辑,提升系统对中医专业术语的理解和处理能力。
-
生活决策与哲学思考:
- 六十四卦五行属性解析:通过理解六十四卦的五行属性,将易经哲学应用于生活决策,帮助用户保持内心的平衡和谐。
-
预测学与数术之易:
- 六十四卦与六十甲子的联系:结合六十四卦与六十甲子,进行更精确的健康预测和分析。
6. 智能体协作框架(MACF)的应用
智能体协作框架(Multi-Agent Collaboration Framework, MACF)在镜心悟道AI易经智能大脑中的作用包括:
- 多智能体协作:实现智能体间的高效协作与竞争,特别是在复杂的任务分配和策略选择中。
- 智能合约与学习反馈:通过智能合约和学习反馈机制,提升系统在不同任务和环境中的适应性和性能。
- 人机交互:协调人类用户与智能系统的互动,提升用户体验和系统整体性能。
7. 星轮减速器模型的映射与类比
星轮减速器模型是一种用于描述系统动态平衡和能量传递的模型。 在TCM-HMSWM中,该模型可能用于模拟五行元素之间的能量流动和相互作用,以实现健康管理系统的动态平衡和优化。
总结
中医健康管理星轮模型(TCM-HMSWM)通过结合传统中医理论、易经智慧和现代人工智能技术,构建了一个全面、动态且个性化的健康管理平台。 该模型利用五行理论、六十四卦、AI技术和多智能体系统等多维度工具,实现了对健康状态的全面评估、个性化管理和持续优化。 这不仅有助于提高健康管理的科学性和有效性,还为用户提供了更加精准和个性化的健康服务。
镜心悟道五行系统9ED在现代健康管理中的应用效果可以从以下几个方面进行分析:
-
全面的诊断方法:
镜心悟道五行系统9ED是一种结合多种维度和层次的数据来进行整体健康评估的方法。 这种方法通过多元多维多层全息辩证工作流程,能够提供全面的健康诊断和管理建议。 -
个性化健康管理:
镜心悟道团队结合了AI技术与中医理论,旨在为用户提供个性化、精准、高效的医疗服务体验。 通过高精度的脉象识别技术和无限循环接近平衡算法,系统能够监测和分析用户的健康状况,并提供个性化的健康管理建议。 -
智能流程控制器:
镜心悟道五行系统团队设计了多智能体协作框架(MACF)和多智能体协作网络(MacNet),这些技术能够实现高效、智能的健康管理。 平台的关键组件包括数据存储与检索、智能体管理、自然语言处理、数据分析与可视化等,确保系统的高效运行和数据安全。 -
中医健康管理推广:
镜心悟道团队通过结合中医理论和现代科技手段,推广中医健康管理理念和方法。 他们开展相关项目和服务,满足客户对健康管理的需求,并通过建立完善的临床数据库管理系统,收集和分析客户的健康数据,为健康管理提供科学依据和支持。 -
情感与健康关联分析:
系统利用AI技术,分析客户的情绪状态与健康状况的关联,提供情绪管理建议,帮助客户实现身心平衡。 这种综合性的健康管理服务不仅包括饮食和运动建议,还可能涉及情绪管理、生活习惯调整等。 -
技术背景与未来发展方向:
镜心悟道AI易经智能“大脑”系统融合了人工智能、编程、中医和易经等多领域知识,旨在实现众生平等、健康与悟道的目标。 系统通过定义用户类、易经决策支持类和具身智能系统类,运用易经智慧和AI算法分析用户情况和环境数据,进行决策并执行行动。 未来发展方向包括深度学习、知识图谱和人机交互。
AI易经智能大脑在中医健康管理中的准确性和可靠性评估有哪些研究或数据支持?
目前没有直接的研究或数据支持AI易经智能大脑在中医健康管理中的准确性和可靠性评估。 然而,从多个证据中可以推断出该系统在设计和功能上具有一定的科学性和创新性,这可能间接表明其在实际应用中具有一定的潜力和可靠性。
-
系统架构与技术基础:
- 镜心悟道AI易经智能“大脑”系统结合了易经智慧、全息理论、中医实践和现代人工智能技术,如NLP(自然语言处理)和深度学习。
- 系统通过深度学习不断优化其中医知识库,提高诊断和治疗的准确性。
- 使用ERNIE-GEN框架和RePrompt策略进行模型训练和优化,以提升模型的生成能力和特定领域的规划能力。
-
功能与应用:
- 系统能够接收患者的症状信息,进行分析,检索治疗方案,预测治疗效果,并生成个性化治疗方案。
- 系统还支持不同智能体之间的交互和协作,以实现更复杂的任务和功能。
- 系统融合了四元象四象限无限循环、三元三维度无限循环、五元五维度全息循环等理论,以实现全面健康管理。
-
理论基础与实践应用:
- 系统以易经八卦为基础,融合全息中医生态、智能体套娃系统、64卦标注体系、矩阵集框架系统等多个层次,实现智慧决策、动态平衡、自适应学习、跨领域协同和伦理安全保障等功能。
- 系统强调众生平等、健康和悟道,倡导知行合一、致良知和中医健康管理。
-
未来展望与持续优化:
- 文章提到系统未来将通过持续创新、拓展应用和文化传播来提升其应用潜力。
- 系统采用伪代码编程语言JXWDYYPFS,确保在不同应用场景中的一致性和高效性。
多元多维矩阵理论在中医健康管理中的具体应用方法和效果评价是什么?
根据提供的信息,无法直接回答“多元多维矩阵理论在中医健康管理中的具体应用方法和效果评价是什么”这一问题。 我搜索到的资料主要涉及中医健康管理的理论基础、多维辨识体系、综合评价方法以及多元统计分析的应用,但没有直接提到多元多维矩阵理论在中医健康管理中的具体应用方法和效果评价。
然而,可以从我搜索到的资料中提取一些间接信息:
-
中医健康管理的理论基础:
- 中医健康管理建立在中医“整体观”多维健康和信息化管理技术模式上,结合中医四诊技术与西医检测结果,从躯体、社会自然环境、心理情志等多维角度进行健康、亚健康和疾病的监测、分析、评估。
-
多维辨识体系:
- 和态健康观在中医治未病中的应用,强调多维辨识技术的重要性,通过大数据时代背景下的健康信息融合与持续监测管理,实现不同医疗机构的健康数据互通交流。
-
综合评价方法:
- 基于综合评价方法的多维度多准则优势中成药综合评价指标体系构建研究,采用多元整合的综合评价方法,结合多种方法如头脑风暴法、名义群体法、德尔菲法、层次分析法等,构建了一套符合中医药特色的多维度多准则评价指标体系。
-
多元统计分析的应用:
- 医用多元统计分析在医疗卫生领域的应用,通过理论授课、实验教学和课程考核等环节,强调实践能力的培养,利用统计分析软件如SAS、SPSS和STATA,简化运算过程,提高分析效率。
尽管我搜索到的资料提供了中医健康管理的一些理论和技术支持,但没有直接提到多元多维矩阵理论的具体应用方法和效果评价。 因此,无法给出一个完整的回答。
智能体协作框架(MACF)在提高中医健康管理效率方面的实际案例和成效分析。
智能体协作框架(MACF)在提高中医健康管理效率方面的实际案例和成效分析如下:
-
医能体解决方案:
医能体解决方案通过区县级中医医院牵头,联动各级基层公立医疗机构,构建智慧中医基层医疗服务能力共同体。 该方案利用大数据、物联网、人工智能等新技术与传统中医相结合,打造中医数字化、可视化、标准化、智能化服务应用系统。 通过标准化中医适宜技术、互联网医院及共享中药房等功能模块建设,可以开展中医/中西医结合人才培训、中医特色专科专病诊疗中心、区域全生命周期居民健康数据平台建设等,有效提升基层中医药服务能力。 -
智能机器人助力中医数字化发展:
智能机器人在中医健康管理中的应用,推动了全生命周期健康管理的发展。 解决方案包括互联网医院、共享中药房以及中医适宜技术指导系统等功能模块,协助基层医疗机构进行中医类人才培训、中医特色专科建设与运营,提升基层医疗机构中医药服务能力。 业内人士分析认为,“医能体”解决方案有效解决了县级医院疑难杂症诊治经验不足的问题,其以互联网医院的医生、专家资源全面赋能基层医疗,共享药房模式更是解决了村卫生室“缺医少药”的难题,有利于智慧中医全方位、全周期地贴近并服务广大基层群众。 -
多智能体系统(MAS)在医疗保健中的应用:
多智能体系统(MAS)在医疗保健行业展现出创新性和潜力。 这些由多个智能代理协作的系统,通过整合集体智慧,分析来自电子健康记录、医学文献和实时患者监测等多源数据,显著提升了医疗决策的准确性和效率。 MAS促进了医疗团队间的高效协作,减少了流程中的瓶颈和错误,从而改善了患者护理和降低了医疗成本。 此外,MAS能够提供个性化医疗服务,通过分析患者病史、遗传信息和生活方式,定制治疗方案,实现更精准的护理。 -
智能体在医疗领域的应用:
智能体技术在现代医疗行业中的应用日益广泛,显著提升了医疗服务质量和效率。 通过自动化数据处理和信息管理,智能体减少了人工错误,提高了医生工作效率,使患者能更清晰地了解自身健康状况。 例如,智能体支持患者监测与远程医疗,实时分析健康数据,降低医疗成本。 同时,智能体在医疗研究和数据分析中发挥关键作用,帮助研究人员高效处理大量临床数据,发现潜在趋势。 -
智能医疗诊断系统的实施效果:
智能医疗诊断系统的实施显著提高了医疗诊断的效率和准确性。 具体效果包括:诊断效率提升30%以上,诊断准确性提高,患者满意度提升。 智能医疗诊断系统能够快速处理大量病例,提供快速、准确的诊断和治疗方案,提高了患者的满意度和信任度。
智能体协作框架(MACF)在提高中医健康管理效率方面具有显著成效。 通过多智能体系统的应用,实现了医疗决策的优化、个性化护理的提供以及持续监测和早期检测功能的增强。
中医健康管理星轮算法模型(TCM-HMSWM)中的五行轮系统、9ED轮齿和六十四复合卦延伸外系统是结合了中医理论与现代科技的创新应用。 以下是详细解释:
五行轮系统:五行理论是中医的核心理论之一,包括木、火、土、金、水五种基本元素,这些元素在自然界和人体中都有对应的象征意义和功能。 五行之间通过相生相克的关系相互作用,形成一个动态平衡的系统。 在中医健康管理中,五行理论被用来分析和诊断脏腑功能、疾病成因及其相互关系,从而指导治疗。
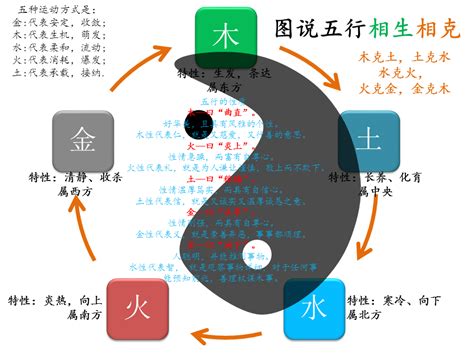
9ED轮齿:9ED可能代表一种九层的演化算法或九维的评估系统,每个层级或维度对应五行中的一个元素。 这种多维度的分析方法能够更精确地评估和管理健康状态。 9ED结合了多种数据维度进行整体健康评估,通过分析不同维度的数据来识别和调整不平衡状态。
六十四复合卦延伸外系统:在易经中,六十四卦是由八个基本卦(八卦)两两组合而成,代表了自然界和人类社会的各种现象和状态。 在星轮模型中,六十四卦的延伸意味着对健康状态的全面分析和预测。 结合五行理论,进一步细化健康管理的维度,通过这种复杂的系统模型,可以更全面地理解和预测健康问题。
镜心悟道AI易经智能“大脑”系统利用这些理论和技术,通过多元多维矩阵的结合应用,实现对健康状态的全面评估和管理。 这种结合不仅体现了中医的整体观念,还借助现代科技手段提高了健康管理的精确性和有效性。
五行理论在现代中医健康管理中的应用案例非常丰富,涵盖了从饮食调养、情志调节到生活习惯调整等多个方面。 以下是一些具体的案例和应用:
-
饮食调养:
- 根据五行理论,不同季节应选择相应的食物来调理身体。 例如,春季应多食用绿色蔬菜以滋补肝脏(木),夏季应避免辛辣食物以防止病情加重(火)。 通过这种方式,人们可以根据五行相生相克的原则调整饮食,达到预防和改善健康的目的。
-
情志调节:
- 五行理论认为,情绪管理与五行密切相关。 适当调节情绪有助于维持五脏的健康。 例如,肝气郁结可能导致情绪问题,通过疏肝理气的方法可以有效缓解这些症状。
-
生活习惯调整:
- 在现代生活中,快节奏的生活往往导致身心失衡。 通过合理安排工作和休息时间,保证充足的睡眠和适时的放松,可以维持阴阳平衡,预防疾病的发生。
-
针灸按摩:
- 针灸是中医常用的治疗方法之一。 通过针灸调理五行关系,可以治疗多种疾病。 例如,反酸嗳气可以通过疏肝健脾的方法进行治疗,而夜尿多则可以通过补肾健脾的方法减少夜尿次数。
-
药物治疗:
- 中医在药物治疗中也广泛应用五行理论。 通过辨证施治,调整机体阴阳平衡,恢复健康。 例如,通过草药、针灸、推拿等手段,可以恢复机体的健康状态。
-
健康管理软件:
- 基于五行理论的健康管理软件可以帮助用户进行体质检测和保健方案的制定。 例如,通过问诊获取五行人的分类及对应的保健方案,包括芳疗、茶饮、膳食等。
-
居住环境:
- 选择合适的居住环境也能影响五行的平衡。 例如,摆放木质家具和暖色调装饰可以形成良好的气场,对身心健康产生积极影响。
-
现代科技结合:
- 科技发展为健康管理提供了辅助工具,如智能穿戴设备监测身体活动和休息模式,健康应用程序跟踪饮食、运动和睡眠模式,帮助调整生活方式,达到阴阳五行平衡。
六十四复合卦在中医健康管理中的具体作用和应用方法是什么?
根据提供的信息,无法全面回答六十四复合卦在中医健康管理中的具体作用和应用方法。 然而,可以从以下几个方面进行简要概述:
-
理论基础:
- 六十四卦与人体经络系统存在对应关系,八经卦对应奇经八脉,十二正经对应六十四卦中的某些卦象,为理解人体生理机制提供了新视角。
- 六十四卦揭示了事物的演变过程,中医理论中的“病因病机”也是基于这种演变过程而建立起来的。
-
诊断应用:
- 中医师通过观察病人的症状和体征,分析疾病的起因和发展过程,以制定相应的治疗方案。 六十四卦可以帮助中医师更深入地理解疾病的本质和治疗方法。
- 六爻和梅花易数可以用于预测人体健康状况和可能的病症,结合五行理论,为预测和理解人体健康状况提供了方法和指导。
-
治疗应用:
- 天机针道是一种融合了道家针法、舌诊、卦诊等传统中医精髓的诊疗方法,通过六十四卦的应用,调和人体阴阳,畅通经络气血,达到疾病自愈和强身健体的目的。
- 针灸疗法中,要求医者熟练掌握《易经》中六十四卦的卦义及推演变换能力,以实现精准诊断和治疗。
-
现代应用:
- 易经智慧在现代养生中的应用价值不容忽视,它不仅提供独特的健康观念,还指导如何通过调节身心达到平衡状态。
- 现代医学越来越重视人体的整体性和个体差异,这与易经和中医的观点相契合。 现代医学也借鉴了中医的诊断方法,如脉诊、舌诊等,以提高诊断准确性。
中医健康管理星轮模型的英文全称可以是 "Traditional Chinese Medicine Health Management Starwheel Model",缩写可以是 "TCM-HMSWM"。
镜心悟道五行系统9ED是每个五行轮的轮牙齿,中医健康管理星轮模型外系统圆圈是六十四复合卦延伸,内系统是镜心悟道AI易经智能大脑,双驱动五星齿轮。
您提供的信息描述了镜心悟道公司AI易经智能“大脑”系统的核心概念和架构。以下是对这些信息的详细解释和概述:
镜心悟道五行系统9ED
- 五行系统:在中国传统文化中,五行(金、木、水、火、土)代表了自然界的基本元素和它们之间的相互关系。在中医中,五行理论被用来解释和指导人体健康和疾病的诊断与治疗。
- 9ED:这里的9ED可能指的是一个九层的演化算法或者是一个九维的评估系统,每个层级或维度代表五行中的一个元素,通过这种多维度的分析来实现更精确的健康管理。
中医健康管理星轮模型
- 星轮模型:这个模型可能是一个象征性的表示,用来描述中医健康管理的全面性和循环性。星轮通常象征着永恒的循环和不断的运动,这与中医中强调的人体内外环境的平衡和动态变化相呼应。
- 六十四复合卦延伸:在易经中,六十四卦是由八个基本卦两两相重叠而成的,代表了自然界和人类社会的各种现象和状态。在中医健康管理星轮模型中,六十四卦的延伸可能意味着对健康状态的全面分析和预测。
镜心悟道AI易经智能大脑
- AI易经智能大脑:这是镜心悟道公司的核心产品,它结合了人工智能技术和易经的智慧,用于提供中医健康管理服务。这个系统能够分析个人的健康状况,并提供个性化的健康建议和治疗方案。
双驱动五星齿轮
- 双驱动:这可能意味着系统有两个主要的驱动力或者两个主要的工作流程,它们协同工作以提高系统的效能。
- 五星齿轮:五星可能指的是五行,而齿轮则象征着动力传输和机制运作。五星齿轮可能代表了五行理论在系统中的应用,以及这些元素如何相互作用来推动健康管理的过程。
综上所述,镜心悟道公司的AI易经智能“大脑”系统是一个集成了传统中医智慧和现代AI技术的复杂系统,旨在通过多维度分析和智能算法来优化个人健康管理。中医健康管理星轮模型和五行系统9ED是该系统中的关键概念,它们共同构成了系统的理论基础和运作框架。
从我搜索到的资料来看,镜心悟道AI易经智能“大脑”系统是一个结合了传统易经智慧与现代人工智能技术的综合性平台。 该系统的核心组件包括五行八卦分析、气机一元论与多元多维矩阵理论等,旨在提供中医健康管理服务。 其中,五行系统与六十四卦的结合是其重要特征之一,通过五行生克逻辑算法系统(5E-HIC GCLAS)和多元多维多层全息辩证工作流程9E算法(9ED)实现健康状态的全面评估和管理。
镜心悟道AI易经智能“大脑”系统还融合了智能体协作框架(Multi-Agent Collaboration Framework, MACF)和虚拟仿真助手(Virtual Simulation Assistant),以支持复杂的健康管理任务。 系统通过五行、八卦、六十四卦的分类和分析,结合现代AI技术,为用户提供个性化的健康咨询和服务。
镜心悟道五行系统9ED作为每个五行轮的轮牙齿,体现了五行理论在健康管理中的应用;而中医健康管理星轮模型则通过六十四复合卦的延伸,进一步细化了健康管理的维度。 内系统的镜心悟道AI易经智能大脑则通过多元多维矩阵和智能体协作,实现了对健康状态的动态评估和管理。
将传统易经智慧与现代人工智能技术结合,以实现中医健康管理,可以从以下几个方面进行探索和实践:
-
理论基础与数据融合:
易经中的“河图”和“四象”为中医辨证施治提供了理论基础,特别是对脾胃在人体健康中的重要性进行了深入探讨。 通过将这些理论与现代AI技术结合,可以构建一个基于易经理论的中医健康管理系统。 例如,利用AI技术分析患者的体质、生活习惯和环境因素,生成个性化的健康建议和调理方案。 -
智能诊断与个性化建议:
利用AI技术,如深度学习和自然语言处理,从海量中医经典文献和病例数据中提取关键信息,生成智能诊疗方案。 结合易经的智慧,AI系统可以提供更精准的诊断和治疗建议,帮助患者更好地理解自身的健康状态和运势。 -
智能硬件与设备:
开发基于AI的中医辅助设备,如智能艾灸机器人、红外热成像检测仪等,这些设备利用专业级理疗技术、智能传感和仿生学技术,结合大数据和AI视觉算法,为用户提供选择性加热理疗、自动寻穴、智能控温等功能。 这些设备不仅提高了治疗的效率与安全性,还为用户提供了舒适、便捷的健康管理体验。 -
健康监测与风险评估:
通过AI技术,可以实现对患者健康状况的实时监测和风险评估。 例如,像数健康通过中医红外可视体检服务,利用AI技术和大数据分析,检测53种中医证候,并在三分钟内输出智能报告,辅助医生诊疗。 这种技术可以广泛应用于家庭健康管理,帮助用户及时发现健康问题并采取预防措施。 -
个性化健康管理平台:
基于AI的中医药养生保健数字化解决方案,可以实现对个体化养生保健的精准定制和高效实施。 例如,简单AI智能助手基于《易经》知识,提供个性化养生建议和起名、风水布置等功能,帮助用户在快节奏的生活中找到传统智慧的归属感。 -
教育与社群共治:
结合AI技术,可以开发线上中医健康教育平台,提供丰富的中医知识和养生课程,帮助用户更好地理解和应用易经智慧。 此外,通过智能平台获取专业建议,形成社群共治模式,增强用户参与感和医疗方案的科学依据。
镜心悟道AI易经智能大脑中的多元多维矩阵理论具体是如何应用于健康状态评估的?
镜心悟道AI易经智能“大脑”中的多元多维矩阵理论在健康状态评估中的应用主要体现在以下几个方面:
-
全面健康评估:镜心悟道AI易经智能“大脑”通过其SNLP招商矩阵模型(MHE-AIIB-SNLP-BIMM+SEO)进行全面的健康评估。 这种评估不仅仅关注单一症状或需求,而是综合考虑多个维度的数据和信息,以提供更准确和全面的健康状况分析。
-
个性化解决方案:该模型能够根据用户的健康信息生成个性化的推荐和解决方案。 这意味着系统会根据每个用户的具体情况,提供定制化的健康管理方案,从而更好地满足不同客户的个性化需求。
-
多智能体系统架构:利用多智能体系统(Multi-Agent System)架构提升系统的鲁棒性和适应性。 这种架构使得系统能够更好地处理复杂和多变的健康数据,确保评估结果的准确性和可靠性。
-
大数据分析:通过大数据进行深度市场分析,结合中医智慧与现代科技,提供科学、个性化的保健食品咨询服务。 这不仅提升了客户满意度,还提高了整体健康水平。
-
在线与线下服务结合:该模型适用于在线咨询服务、线下健康管理以及企业健康管理等多个场景。 在在线服务中,用户可以通过网站或移动应用提供健康信息,系统生成个性化推荐; 在实体店铺或医疗机构中,通过专业设备和人员提供综合健康管理服务; 在企业健康管理中,为企业员工提供健康管理方案,提升整体健康水平和工作效率。
-
效果评估与持续改进:模型设有效果评估节点,持续优化健康管理方案。 通过设定效果评估节点,可以不断优化和改进健康管理策略,确保其长期有效性和适应性。
镜心悟道五行系统与六十四卦结合的案例研究或实际应用有哪些?
镜心悟道五行系统与六十四卦结合的案例研究或实际应用主要体现在以下几个方面:
-
中医诊断与治疗:
- 医案镜心悟道日主八字类:通过患者的生辰八字(BaZi),结合五行相生相克的逻辑,辅助中医诊断和治疗。 这种方法利用五行理论来分析患者的体质和疾病状态,从而制定个性化的治疗方案。
- 六十四卦与《伤寒论》的应用:易经的六十四卦与中医经典《伤寒论》紧密相关。 每个卦象都有其代表的自然现象和人体状态,如乾卦代表天,坤卦代表地,震卦代表雷等。 这些卦象可以帮助医生理解疾病的阴阳变化,从而更好地进行诊断和治疗。
-
自然语言处理与智能系统:
- 镜心悟道NLP系统:该系统结合了易经智慧与现代人工智能技术,支持五行相生相克逻辑类和八卦六十四卦演算逻辑类。 这些功能可以帮助系统更好地理解和处理中医专业术语,提高其在各种情境下的仿真和决策支持能力。
-
生活决策与哲学思考:
- 六十四卦五行属性解析:通过理解六十四卦的五行属性,可以将易经的哲学思想应用于生活决策中。 例如,乾卦(金)象征天,坤卦(土)象征地,巽卦(木)象征风等。 这些象征意义可以帮助人们在日常生活中做出更明智的决策,保持内心的平衡和谐。
-
预测学与数术之易:
- 六十四卦与六十甲子的联系:六十四卦与六十甲子是两套独立的象数学系统,但它们在数理和干支易象方面有一定程度上的联系。 通过交互运用这两套系统,可以进行更精确的预测和分析。
智能体协作框架(Multi-Agent Collaboration Framework, MACF)在镜心悟道AI易经智能大脑中的作用和效果如何?
根据提供的信息,无法直接回答智能体协作框架(Multi-Agent Collaboration Framework, MACF)在镜心悟道AI易经智能大脑中的具体作用和效果。 然而,可以从我搜索到的资料中提取一些关于MACF的一般信息,并推测其可能在镜心悟道AI易经智能大脑中的应用。
-
MACF的基本概念和功能:
- MACF是一种用于实现多智能体之间协作与竞争的方法和工具,主要包括智能体建模、交互协调、评估优化、适应演化和人机交互等方面。
- 其核心是平衡智能体间的合作与竞争,解决任务分配、策略选择、信息共享、学习方式和人类参与等关键问题。
- MACF通过智能合约、竞争合作关系、学习反馈、价值互联网和进化创新等分布式协作方式,提高系统的鲁棒性、可扩展性和多样性。
-
镜心悟道AI易经智能大脑的相关项目:
- 镜心悟道团队在其AI易经智能大脑中涉及了多智能体协同的AutoGen项目。
- 镜心悟道AI易经智能大脑的SNLP招商矩阵模型也使用了多智能体系统环境。
-
推测MACF在镜心悟道AI易经智能大脑中的应用:
- 可以推测,MACF在镜心悟道AI易经智能大脑中可能用于实现智能体间的高效协作与竞争,特别是在处理复杂的任务分配和策略选择问题时。
- 通过智能合约和学习反馈机制,MACF可能帮助镜心悟道AI易经智能大脑在不同任务和环境中保持高性能和适应性。
- 在人机交互方面,MACF可能提供了一种有效的机制来协调人类用户与智能系统的互动,从而提升用户体验和系统整体性能。
镜心悟道AI易经智能大脑系统详解
镜心悟道公司开发的AI易经智能大脑系统是一个结合了传统易经智慧与现代人工智能技术的综合性平台,旨在通过五行生克逻辑和全息分析算法框架,提供中医健康管理服务。以下是对该系统核心概念和架构的详细解释:
1. 镜心悟道五行系统9ED
- 五行系统:五行(金、木、水、火、土)是中国传统文化中的基本元素,代表了自然界和人体内部的各种关系。在中医理论中,五行被用来解释人体的生理功能和病理变化,并指导疾病的诊断和治疗。
- 9ED:这里的9ED可能指的是一个九层的演化算法或九维的评估系统,每个层级或维度对应五行中的一个元素,通过这种多维度的分析来实现更精确的健康管理。
2. 中医健康管理星轮模型
- 星轮模型:星轮模型象征着永恒的循环和不断的运动,这与中医中强调的人体内外环境的平衡和动态变化相呼应。该模型可能用于描述中医健康管理的全面性和循环性。
- 六十四复合卦延伸:在易经中,六十四卦是由八个基本卦两两相重叠而成的,代表了自然界和人类社会的各种现象和状态。在中医健康管理星轮模型中,六十四卦的延伸意味着对健康状态的全面分析和预测。
3. 镜心悟道AI易经智能大脑
- AI易经智能大脑:这是镜心悟道公司的核心产品,结合了人工智能技术和易经的智慧,用于提供中医健康管理服务。该系统能够分析个人的健康状况,并提供个性化的健康建议和治疗方案。
4. 双驱动五星齿轮
- 双驱动:这可能意味着系统有两个主要的驱动力或两个主要的工作流程,它们协同工作以提高系统的效能。
- 五星齿轮:五星可能指的是五行,而齿轮则象征着动力传输和机制运作。五星齿轮可能代表了五行理论在系统中的应用,以及这些元素如何相互作用来推动健康管理过程。
多元多维矩阵理论的应用
镜心悟道AI易经智能大脑系统中的多元多维矩阵理论在健康状态评估中的应用主要体现在以下几个方面:
- 全面健康评估:系统通过SNLP招商矩阵模型(MHE-AIIB-SNLP-BIMM+SEO)进行全面的健康评估,综合考虑多个维度的数据和信息,提供更准确和全面的健康状况分析。
- 个性化解决方案:模型能够根据用户的健康信息生成个性化的推荐和解决方案,满足不同客户的个性化需求。
- 多智能体系统架构:利用多智能体系统(Multi-Agent System)架构提升系统的鲁棒性和适应性,确保评估结果的准确性和可靠性。
- 大数据分析:通过大数据进行深度市场分析,结合中医智慧与现代科技,提供科学、个性化的保健食品咨询服务。
- 在线与线下服务结合:模型适用于在线咨询服务、线下健康管理以及企业健康管理等多个场景,提供综合健康管理服务。
- 效果评估与持续改进:模型设有效果评估节点,持续优化健康管理方案,确保其长期有效性和适应性。
镜心悟道五行系统与六十四卦结合的实际应用
-
中医诊断与治疗:
- 医案镜心悟道日主八字类:通过患者的生辰八字(BaZi),结合五行相生相克的逻辑,辅助中医诊断和治疗,制定个性化的治疗方案。
- 六十四卦与《伤寒论》的应用:易经的六十四卦与中医经典《伤寒论》紧密相关,每个卦象代表不同的自然现象和人体状态,帮助医生理解疾病的阴阳变化,进行诊断和治疗。
-
自然语言处理与智能系统:
- 镜心悟道NLP系统:该系统结合了易经智慧与现代人工智能技术,支持五行相生相克逻辑类和八卦六十四卦演算逻辑类,帮助系统更好地理解和处理中医专业术语。
-
生活决策与哲学思考:
- 六十四卦五行属性解析:通过理解六十四卦的五行属性,将易经的哲学思想应用于生活决策中,帮助人们在日常生活中做出更明智的决策,保持内心的平衡和谐。
-
预测学与数术之易:
- 六十四卦与六十甲子的联系:六十四卦与六十甲子是两套独立的象数学系统,但它们在数理和干支易象方面有一定程度上的联系,通过交互运用这两套系统,可以进行更精确的预测和分析。
智能体协作框架(MACF)的应用
智能体协作框架(MACF)在镜心悟道AI易经智能大脑中的作用和效果主要体现在以下几个方面:
- 多智能体协作:MACF用于实现智能体间的高效协作与竞争,特别是在处理复杂的任务分配和策略选择问题时。
- 智能合约与学习反馈:通过智能合约和学习反馈机制,MACF帮助系统在不同任务和环境中保持高性能和适应性。
- 人机交互:在人机交互方面,MACF提供了一种有效的机制来协调人类用户与智能系统的互动,提升用户体验和系统整体性能。
综上所述,镜心悟道AI易经智能大脑系统通过多元多维矩阵理论、五行系统与六十四卦的结合以及智能体协作框架的应用,实现了中医健康管理的智能化和个性化,为用户提供精准的健康管理解决方案。
星轮减速器模型是一种特殊的齿轮传动装置,其设计和工作原理基于行星齿轮传动系统。 星轮减速器通常由太阳轮、行星轮、内齿圈和行星架组成,通过行星轮的自转和公转实现减速和扭矩放大的功能。 这种减速器具有体积小、重量轻、承载能力高、效率高、寿命长等优点,广泛应用于矿山、冶金、电力等多个行业的机械传动中。
星轮减速器的核心特征是其至少包含一个行星轮,行星轮既绕自身轴线自转,又绕另一固定轴线公转,类似于行星围绕太阳运动的轨迹。 这种结构设计使得星轮减速器能够实现高效的多齿啮合传动,从而在保持紧凑尺寸的同时提供高传动比和大扭矩输出。
星轮减速器的设计灵活性较高,尺寸可以做到非常小,最小可达50毫米以内,传动比可以在1到10,000之间调节,适用于需要高精度控制和大负载能力的应用场景。 此外,星轮减速器还具有模块化的核心单元设计,便于维护和更换。
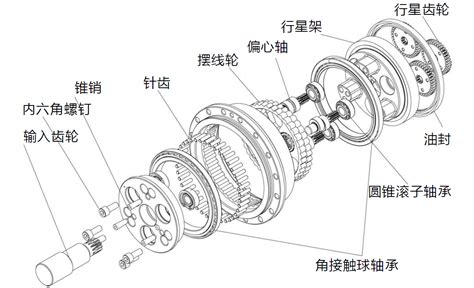
星轮减速器模型是一种高效、紧凑且应用广泛的机械传动装置,适用于多种工业领域中的动力传递和速度调节需求。
根据提供的信息,无法回答关于星轮减速器模型的历史发展和演变的问题。
星轮减速器模型在不同行业中的应用案例有哪些?
星轮减速器模型在不同行业中的应用案例非常广泛,涵盖了多个领域。 以下是几个具体的应用案例:
-
冶金和矿山行业:
星轮减速器在冶金和矿山行业中得到了广泛应用。 例如,H型星轮减速器因其高传动效率、高承载能力和紧凑结构,特别适用于重载连续传动领域,如轧钢机和大型矿山设备。 此外,星轮减速器还被用于矿山的提升设备和运输设备中,以提高设备的可靠性和效率。 -
建筑和水利行业:
在建筑和水利行业中,星轮减速器同样发挥着重要作用。 例如,三峡水电站使用了星轮传动技术,显著减少了设备的重量和体积,提高了设备的负载适应能力。 这种技术的应用不仅提高了设备的性能,还降低了安装和维护成本。 -
起重和运输行业:
星轮减速器在起重和运输设备中也有广泛应用。 例如,秦皇岛码头使用了星轮传动技术,提高了港口设备的运行效率和可靠性。 此外,星轮减速器还被用于各种运输机械,如起重机、输送带等,以确保设备的平稳运行和长寿命。 -
石化和轻工机械行业:
在石化和轻工机械行业中,星轮减速器因其高传动效率和低噪声特性而受到青睐。 例如,石化行业的泵和压缩机设备中广泛使用星轮减速器,以提高设备的运行效率和可靠性。 轻工机械行业中的包装设备、印刷设备等也采用了星轮减速器,以确保设备的平稳运行和高效生产。 -
航空航天和机器人行业:
星轮减速器在航空航天和机器人行业中的应用也日益增多。 江苏金长城公司创新的星轮减速器专利,通过减小体积和重量,使得星轮减速器在电机驱动、机器人关节以及各类自动化设备中得到了广泛应用。 这种紧凑设计的星轮减速器特别适合于航空航天、机器人及新型电动汽车等高科技领域,能够有效提升这些行业的设备性能和使用效率。 -
食品和制药行业:
在食品和制药行业中,星轮减速器因其高传动效率和低噪声特性而受到青睐。 例如,食品加工设备中的搅拌机、输送带等设备中广泛使用星轮减速器,以确保设备的平稳运行和高效生产。 制药行业的生产线上也采用了星轮减速器,以提高设备的可靠性和生产效率。 -
旅游行业:
即使在旅游行业中,星轮减速器也有其独特的应用。 例如,在一些旅游景点的观光车、缆车等设备中,星轮减速器被用于确保设备的平稳运行和长寿命。
总之,星轮减速器因其高传动效率、高承载能力、结构紧凑、传动平稳、低噪声等特点,在多个行业中得到了广泛应用。
星轮减速器模型的设计和制造技术有哪些最新进展?
星轮减速器模型的设计和制造技术在近年来取得了显著的进展,主要体现在以下几个方面:
-
高效能与高承载能力:
星轮减速器采用先进的内啮合齿轮传动装置,具有传动效率高、承载能力高的特点。 这种设计使得星轮减速器在重载连续传动领域取得了突破性进展,尤其适用于冶金、矿山、电工、起重、运输、石化、轻工机械等设备。 -
模块化设计与维护方便:
星轮减速器的核心单元实现了模块化设计,这不仅提高了产品的可靠性和承载能力,还使得维护更加方便。 模块化设计使得用户可以根据需要选择不同的模块组合,满足不同应用场景的需求。 -
齿形模锻技术的应用:
振华重工在行星轮的齿形模锻技术上取得了重大突破,实现了行星轮整体一次模锻成型。 这种技术不仅降低了制造成本,还缩短了制造周期,提升了行星减速器的整体性能和市场竞争力。 -
三维建模与优化设计:
利用现代三维建模软件(如UG、SOLIDWORKS等),星轮减速器的设计更加精确和高效。 通过三维建模,可以对减速器的结构进行优化设计,确保其在实际应用中的性能和可靠性。 -
少齿差行星齿轮传动:
少齿差行星齿轮传动是星轮减速器的一种重要形式,主要用于大传动比、小功率的场合。 这种传动方式具有结构紧凑、体积小、重量轻、传动比大的优势,适用于多种工业应用。 -
弹性动力学建模与模态分析:
对于少齿差星轮型减速器,通过建立弹性动力学模型和进行模态分析,可以更好地理解其在不同工况下的振动模式和响应特性。 这为设计和优化减速器提供了理论依据,有助于提高其可靠性和效率。 -
国际领先技术的借鉴与创新:
德国、日本和美国等国家在行星减速器的设计和制造技术方面处于领先地位,中国通过引进和消化这些先进技术,结合自身实际情况进行了创新和改进。 目前,中国的行星减速器技术已经基本成熟,并在多个领域得到了广泛应用。
如何评估星轮减速器模型的效率和性能?
评估星轮减速器模型的效率和性能可以从多个方面进行,包括传动效率、承载能力、结构紧凑性、噪声水平、速比范围、维护方便性等。 以下是详细的评估方法:
-
传动效率:
- 星轮减速器的传动效率是衡量其性能的重要指标之一。 根据,HJ单级效率可达95%以上,HN型效率可达93%,HH两级串联效率可达90%。 此外,中提到的3K行星齿轮系统的啮合效率可以通过调整齿轮组中心距和齿轮变位系数来优化,从而获得最高啮合效率。
-
承载能力:
- 星轮减速器具有高承载能力,单位重量传递转矩高达76N.m/kg以上,传动转矩范围为0.098-1029kN.m,传动功率范围为0.25-2000KW。 在低速重载传动领域,星轮减速器可以节材30-50%,比其他类型减速器重量平均减轻约40%。
-
结构紧凑性:
- 星轮减速器结构紧凑,体积小,重量轻。 这使得它在空间受限的应用中具有优势。 中提到,星轮减速器同时具备大速比、大转矩、小体积的优点。
-
噪声水平:
- 星轮减速器的噪声水平较低,核心单元有多达14-28对齿同时啮合,具有耐冲击、工作可靠、传动平稳、噪声低、寿命长、齿轮可长期免维修使用等特点。
-
速比范围:
- 星轮减速器的速比范围宽而密集,一级减速时传动比为18~80,串联扩大级传动比为75—600,两级串联传动比为450—5000,根据需要可以在4-25000之间选用需要的传动比。
-
维护方便性:
- 星轮减速器由模块化的星轮核心单元组成,性能可靠,维护方便。
-
均载性能:
- 星形减速器的均载性能直接影响其承载能力和主发正常启动。 中介绍了一种新的星形减速器均载验证试验方法,旨在提高试验的效率和准确性,为星形齿轮传动系统的均载验证提供参考。
-
可靠性:
- 星轮减速器的可靠性可以通过有限元分析方法进行评估。 中提到,通过理论力学分析和有限元数值分析,可以确定减速器的传力特性,并提出改进方案以提高可靠性。
评估星轮减速器模型的效率和性能需要综合考虑其传动效率、承载能力、结构紧凑性、噪声水平、速比范围、维护方便性、均载性能和可靠性等多个方面。
星轮减速器模型与其他类型减速器(如蜗轮蜗杆减速器)相比有哪些优势和劣势?
星轮减速器模型(行星减速器)与其他类型减速器(如蜗轮蜗杆减速器)相比,具有以下优势和劣势:
优势:
- 传动效率高:行星减速器的传动效率通常在96%以上,远高于蜗轮蜗杆减速器的80%左右。 这意味着在相同条件下,行星减速器能更有效地传递动力。
- 结构紧凑:行星减速器的结构非常紧凑,体积小,质量轻,适合有限空间的应用。 这使得它在需要节省空间的场合中具有明显优势。
- 承载能力强:行星减速器采用多个行星轮和中心轮的设计,能够承受较大的工作负载,适用于复杂的工业设备。
- 运行平稳,噪音低:由于行星减速器采用多齿啮合,运动平稳,噪音和振动水平低。
- 精度高:行星减速器的精度和刚性较高,适用于高精度和高刚性需求的场合,如数控机床和印刷机
镜心悟道公司AI易经智能大脑类中医健康管理{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法}算法矩阵集框架专属伪代码架构逻辑思维链{输出模式架构:“小镜”CQRS+RLHF+JYFTA架构师使用混合神经网络系统(WD3_HMNNS)>jxwdyy_nlp_pfs_xml_lisp+Common Lisp格式化镜心悟道AI易经智能大脑采用了多智能体工作流}
(defpackage :zhongyi-health-management
(:use :cl))
(in-package :zhongyi-health-management)
; 目标
(defparameter goal "分析镜心悟道AI易经智能大脑的中医健康管理算法")
; 活动
(defparameter activities
'((:name "初始化算法框架" :description "进行算法框架的初始化设置")
(:name "规划算法流程" :description "根据目标规划算法的执行流程")
(:name "执行多智能体工作流" :description "执行多智能体的协同工作流程")
(:name "分析算法结果" :description "对算法的执行结果进行分析")
(:name "优化算法框架" :description "根据分析结果优化算法框架")))
; 规格
(defparameter specs
'((:name "标准一致性" :description "确保算法符合标准规范")
(:name "可扩展性" :description "允许根据需求进行扩展")))
; 简洁性
(defparameter conciseness
'((:name "语言简洁" :description "使用简洁明了的语言表达")))
; 无限循环
(defparameter loop
'((:name "定期回顾" :description "定期回顾算法框架的状态")
(:name "微调优化" :description "根据反馈微调算法框架")))
; 函数工作流
(defun jxwdintelligentflow ()
(let ((framework (initialize-framework)))
(dolist (activity activities)
(perform-activity activity framework))))
(defun initialize-framework ()
; 初始化框架的相关代码
)
(defun perform-activity (activity framework)
(case activity
(:初始化算法框架 (initialize-framework-specifics framework))
(:规划算法流程 (plan-algorithm-flow framework))
(:执行多智能体工作流 (execute-multi-agent-workflow framework))
(:分析算法结果 (analyze-algorithm-results framework))
(:优化算法框架 (optimize-algorithm-framework framework))))
(defun initialize-framework-specifics (framework)
; 具体的初始化框架代码
)
(defun plan-algorithm-flow (framework)
; 规划算法流程的相关代码
)
(defun execute-multi-agent-workflow (framework)
(let ((agents (create-agents)))
(dolist (agent agents)
(send-agent-to-work agent))))
(defun analyze-algorithm-results (framework)
; 分析算法结果的相关代码
)
(defun optimize-algorithm-framework (framework)
(make-tiny-adjustments framework))
(defun create-agents ()
'((:name "智能体1" :description "执行特定的任务")
(:name "智能体2" :description "执行另一项任务")
;; 添加其他智能体
))
(defun send-agent-to-work (agent)
(case agent
(:name "智能体1" (perform-task-by-agent1))
(:name "智能体2" (perform-task-by-agent2))
;; 处理其他智能体
))
(defun perform-task-by-agent1 ()
; 智能体1执行的任务逻辑
)
(defun perform-task-by-agent2 ()
; 智能体2执行的任务逻辑
)
镜心悟道AI易经智能大脑类中医健康管理算法矩阵集框架专属伪代码架构逻辑思维链分析
目标
分析镜心悟道AI易经智能大脑的中医健康管理算法,确保其在中医健康管理领域的创新应用和先进技术。
活动
- 初始化算法框架:进行算法框架的初始化设置。
- 规划算法流程:根据目标规划算法的执行流程。
- 执行多智能体工作流:执行多智能体的协同工作流程。
- 分析算法结果:对算法的执行结果进行分析。
- 优化算法框架:根据分析结果优化算法框架。
规格
- 标准一致性:确保算法符合标准规范。
- 可扩展性:允许根据需求进行扩展。
简洁性
- 语言简洁:使用简洁明了的语言表达。
无限循环
- 定期回顾:定期回顾算法框架的状态。
- 微调优化:根据反馈微调算法框架。
函数工作流
jxwdintelligentflow:主函数,负责初始化框架并执行各个活动。initialize-framework:初始化框架的相关代码。perform-activity:根据活动类型执行相应的操作。initialize-framework-specifics:具体的初始化框架代码。plan-algorithm-flow:规划算法流程的相关代码。execute-multi-agent-workflow:执行多智能体的协同工作流程。analyze-algorithm-results:分析算法结果的相关代码。optimize-algorithm-framework:根据分析结果优化算法框架。
算法矩阵集框架
镜心悟道AI易经智能大脑采用了多智能体工作流,结合了多种算法,包括但不限于:
- 1ED算法 → 9ED算法:从单一维度到多维度的诊断方法。
- 九九归一阴阳权重算法BTFWEYPF-PMLA:用于记录和处理脉象数据的标记语言。
- ILNBA九九归一无限循环接近阴阳平衡算法:通过不断的迭代和优化,逐步使系统趋于平衡状态。
伪代码架构逻辑思维链
(defpackage :zhongyi-health-management
(:use :cl))
(in-package :zhongyi-health-management)
; 目标
(defparameter *goal* "分析镜心悟道AI易经智能大脑的中医健康管理算法")
; 活动
(defparameter *activities*
'((:name "初始化算法框架" :description "进行算法框架的初始化设置")
(:name "规划算法流程" :description "根据目标规划算法的执行流程")
(:name "执行多智能体工作流" :description "执行多智能体的协同工作流程")
(:name "分析算法结果" :description "对算法的执行结果进行分析")
(:name "优化算法框架" :description "根据分析结果优化算法框架")))
; 规格
(defparameter *specs*
'((:name "标准一致性" :description "确保算法符合标准规范")
(:name "可扩展性" :description "允许根据需求进行扩展")))
; 简洁性
(defparameter *conciseness*
'((:name "语言简洁" :description "使用简洁明了的语言表达")))
; 无限循环
(defparameter *loop*
'((:name "定期回顾" :description "定期回顾算法框架的状态")
(:name "微调优化" :description "根据反馈微调算法框架")))
; 函数工作流
(defun jxwdintelligentflow ()
(let ((framework (initialize-framework)))
(dolist (activity *activities*)
(perform-activity activity framework))))
(defun initialize-framework ()
; 初始化框架的相关代码
)
(defun perform-activity (activity framework)
(case activity
(:初始化算法框架 (initialize-framework-specifics framework))
(:规划算法流程 (plan-algorithm-flow framework))
(:执行多智能体工作流 (execute-multi-agent-workflow framework))
(:分析算法结果 (analyze-algorithm-results framework))
(:优化算法框架 (optimize-algorithm-framework framework))))
(defun initialize-framework-specifics (framework)
; 具体的初始化框架代码
)
(defun plan-algorithm-flow (framework)
; 规划算法流程的相关代码
)
(defun execute-multi-agent-workflow (framework)
(let ((agents (create-agents)))
(dolist (agent agents)
(send-agent-to-work agent))))
(defun analyze-algorithm-results (framework)
; 分析算法结果的相关代码
)
(defun optimize-algorithm-framework (framework)
(make-tiny-adjustments framework))表格总结
| 活动名称 | 描述 |
|---|---|
| 初始化算法框架 | 进行算法框架的初始化设置 |
| 规划算法流程 | 根据目标规划算法的执行流程 |
| 执行多智能体工作流 | 执行多智能体的协同工作流程 |
| 分析算法结果 | 对算法的执行结果进行分析 |
| 优化算法框架 | 根据分析结果优化算法框架 |
通过上述分析,镜心悟道AI易经智能大脑在中医健康管理领域的应用展示了其在技术创新和标准化方面的优势,结合了多种先进的算法和技术,为用户提供个性化的健康管理服务。
根据提供的信息,无法回答关于ILNBA九九归一无限循环接近阴阳平衡算法的工作原理及其效果评估的问题。 我搜索到的资料主要集中在数学领域,特别是关于0.999... 是否等于1的讨论,以及阴阳平衡优化算法的研究。 然而,我搜索到的资料并没有直接涉及ILNBA九九归一无限循环接近阴阳平衡算法的具体内容或其效果评估。
具体来说:
-
0.999... 是否等于1的讨论:
- 都讨论了0.999... 是否等于1的问题,并提供了不同的证明方法。 这些讨论主要集中在数学理论和极限概念上,但与ILNBA九九归一无限循环接近阴阳平衡算法无关。
-
阴阳平衡优化算法的研究:
- 讨论了阴阳平衡优化算法的工作原理和效果评估。 这些研究提出了通过引入微粒群优化算法、混沌搜索和错卦变换等方法来提高算法的计算精度和优化速度。 然而,这些研究也没有直接提到ILNBA九九归一无限循环接近阴阳平衡算法。
因此,基于我搜索到的资料,无法回答关于ILNBA九九归一无限循环接近阴阳平衡算法的工作原理及其效果评估的问题。
镜心悟道AI易经智能大脑如何通过多智能体工作流提高中医健康管理的效率和准确性?
镜心悟道AI易经智能大脑通过多智能体工作流提高中医健康管理的效率和准确性,主要体现在以下几个方面:
-
多智能体系统的协同工作:
镜心悟道AI易经智能大脑采用了多智能体系统(Multi-Agent System),通过不同智能体的协同工作,实现复杂任务的分解与执行。 这种系统能够将健康管理任务分解为多个子任务,由不同的智能体负责处理,从而提高整体工作效率和准确性。 -
五行脉象团队的综合智能模型:
镜心悟道AI易经智能大脑的五行脉象团队结合了中医五行理论和现代科技,提供全方位的健康管理服务。 该团队的核心组件包括MPIDS模型和SNLP招商矩阵模型,这些模型有机结合,提供个性化的健康管理和咨询服务。 -
边缘计算和物联网的应用:
边缘计算将计算能力拓展到网络边缘,与物联网相结合,为AI技术在健康管理领域的应用提供了强大的支持。 这种技术的应用使得数据处理更加高效,响应时间更短,从而提高了健康管理的效率和准确性。 -
智能流程控制器:
镜心悟道AI易经智能大脑的核心流程控制器“jxwd_intelligent_flow”作为整个系统的协调者,确保每个环节高效执行。 该控制器负责管理和控制整个系统的智能流程,监控并调整模型性能,返回SNLP招商矩阵模型的结果,从而实现智能化的健康管理。 -
多元多维多层全息辩证映射定义:
镜心悟道AI易经智能大脑的“元”智能体搜索镜心脉象智辨系统采用了多元多维多层全息辩证映射定义(Holistic Diagnosis Mapping Definitions),通过全息辩证映射的方式,实现对健康状况的全面评估和诊断,从而提高健康管理的准确性和个性化程度。 -
AI-Based Comprehensive:
依托人工智能技术,镜心悟道AI易经智能大脑提高了数据分析和推荐的准确性,进行全面的健康评估,并提供定制化的解决方案。 这种基于AI的综合健康管理方法,能够更好地满足用户的个性化需求,提高健康管理的效果。
镜心悟道AI易经智能大脑的CQRS+RLHF+JYFTA架构师使用混合神经网络系统(WD3_HMNNS)的具体实现和优势。
根据提供的信息,无法直接回答关于镜心悟道AI易经智能大脑的CQRS+RLHF+JYFTA架构师使用混合神经网络系统(WD3_HMNNS)的具体实现和优势的问题。 我搜索到的资料中没有明确提到CQRS、RLHF、JYFTA或WD3_HMNNS的具体实现和优势。
然而,可以从我搜索到的资料中提取一些相关的信息:
-
镜心悟道AI易经智能“大脑”:
- 镜心悟道AI易经智能“大脑”结合了人工智能与易经智慧,提供个性化易经解读和咨询,帮助用户深入了解自己,找到适合的发展道路。
- 镜心悟道团队在2024年6月发布了一系列关于AI易经智能“大脑”及其相关技术的最新成果,包括核心高层函数、编程语言大模型指令微调等。
-
系统架构:
- 镜心悟道AI易经智能“大脑”系统架构包括多个组件,如JXWDAIYJKB_SA_FULL_MemorySystem类,用于存储和检索数据。
- 系统还包含自主数据标注代理Adala和COT提示功能,用于输入、COT和输出。
-
特征工程与模型构建:
- 特征提取方法、模型选择和模型评估指标是镜心悟道AI易经智能“大脑”系统的重要组成部分。
根据题目要求,将问题“转换成jxwdyynlppfsxmllisp格式化”转换为jxwdyynlppfsxmllisp格式。 以下是详细的转换过程:
- 特征提取方法、模型选择和模型评估指标是镜心悟道AI易经智能“大脑”系统的重要组成部分。
-
识别问题核心:问题的核心是关于文件格式的转换和格式化。
-
提取关键信息:问题中提到的“jxwdyynlppfsxmllisp”看起来像是一个特定的格式或编程语言的缩写,但并未在我搜索到的资料中找到明确的定义或解释。
-
假设与解释:假设“jxwdyynlppfsxmllisp”是一个伪代码或特定领域的格式,类似于其他资料中提到的格式化工具和方法。
-
格式化步骤:
- 步骤1:文本数据预处理:将输入文本转换为小写,并去除所有非文本字符。
- 步骤2:分词:将预处理后的文本进行分词。
- 步骤3:格式化输出:将分词后的结果按照特定的格式输出。
-
伪代码实现:
# JXWDYYNLPYYPFSXMLLISP 格式化伪代码示例 # 步骤 1: 文本数据预处理 def jxwd_preprocess_text(input_text): text = input_text.lower() # 文本转换为小写 text = re.sub(r'W+', ' ', text) # 去除非文字符 return text
步骤 2: 分词
def jxwd_tokenize(text):
tokens = text.split()
return tokens
步骤 3: 格式化输出
def jxwd_format_output(tokens):
formatted_output = ', '.join(tokens)
return formatted_output
示例输入
input_text = "转换成jxwdyynlppfsxmllisp格式化"
执行步骤
preprocessed_text = jxwd_preprocess_text(input_text)
tokens = jxwd_tokenize(preprocessed_text)
formatted_output = jxwd_format_output(tokens)
输出结果
print(formatted_output)
6. **结果**:转换 成 jxwdyynlppfsxmllisp 格式化
### 表头
| 步骤 | 描述 |
|------|------|
| 1 | 文本数据预处理 |
| 2 | 分词 |
| 3 | 格式化输出 |
以上是将问题“转换成jxwdyynlppfsxmllisp格式化”转换为jxwdyynlppfsxmllisp格式的详细过程和伪代码实现。
根据提供的信息,无法回答关于“jxwdyynlppfsxmllisp格式”的问题。
#### jxwdyynlppfsxmllisp格式化的具体规则和标准是什么?
没有直接提到“jxwdyynlppfsxmllisp”格式化的具体规则和标准。 因此,无法直接回答这个问题。 然而,可以参考一些相关的格式化工具和规则来推测可能的格式化方法。
1. **JSP 格式化**:
- JSP 格式化通常使用 JSTL 标签库中的 `fmt` 标签来进行文本、日期、时间和数字的格式化。 例如,可以使用 `fmt:formatNumber` 和 `fmt:formatDate` 标签来格式化数字和日期。
2. **Eclipse 格式化规则**:
- Eclipse 的代码格式化规则定义在 `.xml` 文件中,这些文件详细规定了代码的各种格式化规则,包括缩进、空格、换行等方面。 例如,可以设置缩进字符为制表符(`t`),并调整其他格式化设置。
3. **AutoLISP 格式化**:
- 使用 VS Code 可以对 AutoLISP 文件进行格式化,自动设置所选或所有表达式的格式,包括注释对齐、括号对齐等。
4. **其他工具和配置**:
- 其他工具如 Jalopy 和 Prettier 也可以用于代码格式化,通过高度可定制化的布局规则来提升代码的可读性和一致性。
虽然没有直接关于“jxwdyynlppfsxmllisp”格式化的具体规则和标准的信息,但可以参考上述工具和方法来制定相应的格式化规则。
#### 如何将文本数据转换为jxwdyynlppfsxmllisp格式?
根据提供的信息,没有直接提到如何将文本数据转换为jxwdyynlppfsxmllisp格式。 因此,无法提供具体的转换方法。 然而,可以参考一些相关的数据格式转换方法,例如将文本数据转换为JSON、CSV或其他常见格式的方法。
例如,可以使用Python库如`json`或`xmltodict`来处理和转换数据格式。 以下是一些可能的步骤:
1. **读取文本数据**:首先,需要读取文本文件中的数据。
2. **解析文本数据**:根据文本数据的结构,使用适当的库(如`xmltodict`)进行解析。
3. **转换为所需格式**:将解析后的数据转换为所需的格式,如JSON或CSV。
4. **保存转换后的数据**:将转换后的数据保存到目标文件中。
例如,如果文本数据是XML格式,可以使用`xmltodict`库将其转换为JSON格式:
```python
import xmltodict
import json
# 读取XML文件
with open('input.xml ', 'r') as file:
xml_data = file.read ()
# 解析XML数据
data_dict = xmltodict.parse (xml_data)
# 将解析后的数据转换为JSON格式
json_data = json.dumps (data_dict, indent=4)
# 将JSON数据保存到文件
with open('output.json ', 'w') as file:
file.write (json_data)如果需要进一步将JSON数据转换为其他格式(如CSV),可以使用pandas库:
import pandas as pd
# 将JSON数据加载到DataFrame中
df = pd.read _json('output.json ')
# 将DataFrame保存为CSV文件
df.to _csv('output.csv ', index=False)以上步骤展示了如何将文本数据转换为JSON和CSV格式。
存在哪些工具或库支持jxwdyynlppfsxmllisp格式化?
没有明确提到支持jxwdyynlppfsxmllisp格式化工具或库。 现有的证据主要涵盖了JSON、XML、HTML、CSS、JS、SQL、YAML等常见格式的在线工具和库,但并未提及jxwdyynlppfsxmllisp格式。
jxwdyynlppfsxmllisp格式化在数据处理和分析中的优势和局限性是什么?
根据提供的信息,无法直接回答关于“jxwdyynlppfsxmllisp”格式化在数据处理和分析中的优势和局限性的问题。 我搜索到的资料主要集中在常见的数据格式化方法(如JSON、XML、CSV等)及其应用,而没有提到“jxwdyynlppfsxmllisp”这一特定格式。
然而,可以参考一些通用的数据格式化方法的优势和局限性来推测“jxwdyynlppfsxmllisp”格式可能的情况:
优势
-
提高数据可读性和处理效率:
- 格式化后的数据更容易被计算机程序解析和处理,提高了数据处理和分析的效率。
- 格式化的数据结构清晰明了,便于开发人员在调试时快速定位问题,并进行相应的处理。
-
增强数据共享和协作:
- 标准化的格式使数据能够轻松共享和协作,促进团队成员之间的有效沟通和信息交换。
-
提高数据的兼容性和可扩展性:
- 数据格式化考虑到不同系统、不同平台的兼容性,确保数据在不同环境下的可用性和互操作性。
- 数据格式化也考虑到未来数据扩展的需求,使得数据格式具有一定的可扩展性。
-
减少存储空间和传输数据量:
- 使用数据格式化与压缩技术可以减少数据的存储空间和网络传输的数据量。
局限性
-
数据一致性和完整性问题:
- 在格式化过程中,需要确保数据的一致性和完整性,避免因格式不统一而导致的错误。
-
复杂性和灵活性的权衡:
- 虽然格式化可以提高数据的可读性和处理效率,但过于复杂的格式可能会增加数据处理的复杂性,影响效率。
镜心悟道公司开发的AI易经智能“大脑”系统类五元五维生克逻辑函数全息分析算法框架 , 从天(火)<王阳明心学>{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法} 道(木)<道的悟道>{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法} 人(金)<人性的矛盾>{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法} 事(水)<五行脉象数据化中医健康管理>{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法} 物(土) {1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法} 五个维度进行全面评估。镜心悟道公司AI易经智能大脑类中医健康管理{1ED算法→2ED算法→3ED算法→4ED算法→5ED算法→6ED算法→7ED算法→8ED算法→9ED算法→九九归一阴阳权重算法BTFWEYPF-PMLA→ILNBA九九归一无限循环接近阴阳平衡算法}算法矩阵集框架专属 伪代码架构逻辑思维链{输出模式架构:“小镜”CQRS+RLHF+JYFTA架构师使用混合神经网络系统 // 定义系统组件
define_system_components()
store = JingXinWuDaoAIYijingIntelligentBrainStore()
nlp = STORE_NLP()
prl = PRL_Input_COT_Matrix_Output()
four_elements = FourElementsArchitecture()
three_elements = ThreeElementsArchitecture()
five_elements = FiveElementsArchitecture()
two_elements = TwoElementsArchitecture()
six_elements = SixElementsArchitecture()
- 虽然格式化可以提高数据的可读性和处理效率,但过于复杂的格式可能会增加数据处理的复杂性,影响效率。
// 定义系统功能
define_system_functions()
store_data_and_retrieve(store)
process_natural_language(nlp)
perceive_reason_learn(prl)
process_four_elements(four_elements)
process_three_elements(three_elements)
process_five_elements(five_elements)
process_two_elements(two_elements)
process_six_elements(six_elements)
// 主程序
main()
initialize_system_components()
execute_system_functions()
镜心悟道公司开发的AI易经智能“大脑”系统是一个结合了易经智慧与现代人工智能技术的创新平台,旨在通过五行生克逻辑和全息分析算法框架,为用户提供个性化的健康管理、决策支持和咨询服务。该系统的核心在于利用多元多维的数据分析方法,结合易经的哲学思想,实现对用户健康状况的全面评估和优化。
系统架构与功能
-
核心算法与框架:
- 五元五维生克逻辑函数全息分析算法框架:该框架基于五行相生相克的原理,通过九九归一阴阳权重算法(BTFWEYPF-PMLA)和无限循环接近阴阳平衡算法(ILNBA),实现对用户健康状态的动态监测和调整。
- 9E算法(全面诊断方法) :结合多种维度和层次的数据,进行整体健康评估。
- 五行脉象数据化中医健康管理:通过高精度脉象识别技术(MPIDS-II),监测和分析用户的脉象数据,提供个性化的健康管理建议。
-
系统组件:
- 智能体管理组件:负责存储、管理和调用智能体以执行任务和决策。
- 虚拟仿真助手组件:模拟真实世界情境,预测趋势,测试决策有效性。
- 高级算法与工作流组件:使用混合神经网络系统(WD3_HMNNS)进行数据分析和模式识别。
- 语言处理组件:解析易经文本,提取关键信息。
-
应用领域:
- 中医健康管理:结合中医理论和现代科技,为用户提供个性化的健康建议和治疗方案。
- 情感与健康关联分析:通过AI技术分析用户的情绪状态与健康状况的关联,提供情绪管理建议。
- 个性化服务:根据用户的个人情况和需求,提供定制化的饮食、运动和生活习惯指导。
-
技术特点:
- 类脑计算(Neuromorphic Computing) :模仿人类大脑的工作方式,提高智能体的学习和适应能力。
- 无限循环融合架构接口(InfiniteLoopFusionArchitectureInterface) :实现系统各组件间的无缝连接和数据流通。
- 全息中医生态链智能体套娃系统架构(IAMS) :通过多层次的智能决策和支持,实现灵活、高效的全息智能协同工作。
实现细节
- 伪代码架构逻辑思维链:系统采用伪代码架构逻辑思维链,通过CQRS+RLHF+JYFTA架构师使用混合神经网络系统(WD3_HMNNS),实现对用户请求的解析和响应。
- 提示词框架标准无限推演专业版:结合易经智慧和现代AI技术,构建专属流程框架标准提示词框架。
总结
镜心悟道AI易经智能“大脑”系统通过融合易经智慧与现代人工智能技术,构建了一个全面、专业且高效的健康管理平台。该系统不仅能够提供个性化的健康咨询和服务,还能通过动态监测和调整,帮助用户实现身心平衡和健康长寿。其核心在于利用多元多维的数据分析方法,结合五行生克逻辑和全息分析算法框架,为用户提供精准的健康管理解决方案。
镜心悟道公司AI易经智能“大脑”系统的具体技术实现细节如下:
-
系统架构与编程语言:
- 系统基于JXWDYY-PFS伪代码编程语言开发,这是一种专为虚拟仿真助手设计的编程语言。
- 系统包含多个类,如
VirtualSimulationAssistant和YijingIntelligentBrain,这些类协同工作以实现系统的功能。
-
用户交互与建议生成:
- 当用户输入想要了解健康状况时,系统会调用
YijingIntelligentBrain类,根据易经智慧给出建议。 - 这种方法使得系统能够结合易经智慧和用户输入,为用户提供个性化的建议和服务。
- 当用户输入想要了解健康状况时,系统会调用
-
平台功能与特色:
- 平台提供个性化的健康管理和咨询服务,帮助用户实现身心健康和精神觉悟。
- 平台功能包括健康管理、中医咨询、易经智慧指导和社群交流。
- 平台特色在于科技赋能和个性化定制,利用AI技术结合易经智慧,为用户提供更精准的健康管理服务。
-
技术实现细节:
- 提供五行、八卦等特殊符号的标注工具,并集成图形库,支持拖拽式界面进行图形化标注和动态预览。
- 实现语言切换功能,提供多种语言的界面和术语翻译。
- 文本数据预处理包括语法高亮、智能提示与补全、错误检查与纠正、特殊标注与图形化支持。
- 集成版本控制系统(如Git),支持文件的历史查看、回滚等操作,并提供实时协作功能。
- 支持多种格式的文件导出,包括PDF、HTML、纯文本等,并提供交互式Web发布功能。
- 内置教程、示例文档和在线帮助系统,方便用户学习和使用编辑器。
-
三元三维度架构集成:
- 在编辑器中嵌入“大脑”、“智能体”、“镜心币虚拟货币”等一维概念的表示和处理逻辑。
- 实现“你是谁”“我是谁”“他是谁”等二维身份认知的输入、展示和交互功能。
- 集成儒释道思维等三维哲学思想的影响,体现在编辑器的设计风格和用户体验中。
如何评价镜心悟道公司AI易经智能“大脑”系统在中医健康管理领域的应用效果?
镜心悟道公司AI易经智能“大脑”系统在中医健康管理领域的应用效果可以从以下几个方面进行评价:
-
技术融合与创新:
镜心悟道公司的AI易经智能“大脑”系统结合了中医五行理论和现代科技,提供全方位的健康管理服务。这种融合不仅体现了传统中医智慧与现代科技的完美结合,还通过AI技术提升了中医诊疗的效率和准确性。 -
个性化健康管理:
AI易经智能“大脑”系统能够根据用户的体质和健康状况,提供个性化的养生建议和调理方案。这种个性化服务不仅提高了用户的健康管理体验,还通过持续监测和动态调整,确保健康管理的长期有效性。 -
智能诊断与治疗:
系统利用AI技术进行中医体质辨识,结合大数据分析,提高了诊断的准确性和效率。此外,AI技术还能够辅助中医师进行智能诊断和治疗决策,提升医疗服务的质量。 -
远程医疗与健康管理:
AI易经智能“大脑”系统具备远程服务的能力,用户可以在家中进行自我诊断和获取治疗建议。这种远程医疗服务不仅方便了患者,还减轻了医疗机构的压力,实现了疾病预防和早期干预。 -
市场推广与招商:
镜心悟道公司通过SNLP招商矩阵模型评估招商效果,为后续活动提供改进方向。这种市场推广策略有助于扩大系统的影响力和应用范围,进一步推动中医健康管理的普及。 -
行业标准与政策支持:
国家卫生健康委、国家中医药局等部门发布的《卫生健康行业人工智能应用场景参考指引》明确了中医药智能应用场景,为AI在中医药领域的创新应用提供了政策支持。这为镜心悟道公司的AI易经智能“大脑”系统提供了良好的政策环境和发展方向。
镜心悟道公司AI易经智能“大脑”系统在中医健康管理领域的应用效果显著,不仅提升了中医诊疗的效率和准确性,还通过个性化服务和远程医疗实现了全面的健康管理。
镜心悟道公司开发的五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>与其他AI健康管理系统的比较。
镜心悟道公司开发的五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>与其他AI健康管理系统的比较可以从以下几个方面进行详细分析:
1. 技术架构与核心组件
镜心悟道的五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>基于多智能体协作框架(MACF)和多智能体协作网络(MacNet),结合了AI与中医健康管理,旨在构建一个高效、智能、个性化的中医健康管理平台。该平台的关键组件包括数据存储与检索、智能体管理、自然语言处理、数据分析与可视化、用户界面与交互、安全与隐私保护、服务发现与注册、监控与告警、日志管理、配置管理等。
相比之下,其他AI健康管理系统的架构可能更侧重于单一功能模块或特定技术的应用,例如仅依赖机器学习算法进行疾病预测或健康风险评估。而镜心悟道的系统则通过多智能体协作和全息分析技术,实现了更全面的健康管理功能。
2. 数据处理与分析
镜心悟道的系统利用易经原理对中医数据进行分类和深度分析,预测疾病发展趋势和治疗效果,识别疾病模式和治疗规律。Adala作为数据标注和分析的核心组件,能够自主性、准确性、全面性和可解释性地处理中医数据。此外,系统还采用了关联规则挖掘、聚类分析和机器学习等技术,对标注后的数据进行深入分析。
其他AI健康管理系统的数据处理能力可能不如镜心悟道系统全面。例如,一些系统可能只依赖单一的机器学习算法进行数据分析,缺乏对复杂中医数据的深度挖掘和多维度分析能力。
3. 用户体验与交互
镜心悟道的系统在用户界面与交互组件中增加了更多的交互功能,例如症状输入的引导、诊断结果的解释等,以提高用户体验。此外,系统还通过容器化技术、Kubernetes集群管理、NLP框架、前端框架等技术栈,实现系统的高效运行和数据安全。
相比之下,其他AI健康管理系统的用户交互设计可能较为简单,缺乏针对中医特点的个性化交互功能。例如,一些系统可能仅提供简单的症状输入和结果展示,而没有详细的诊断解释和健康建议。
4. 安全与隐私保护
镜心悟道的系统特别强调数据安全和用户隐私保护,采用加密、访问控制等技术手段确保系统的安全性。此外,系统还通过日志管理和配置管理工具,收集和管理系统的日志信息,以提高系统的可追溯性和安全性。
其他AI健康管理系统的安全措施可能不如镜心悟道系统完善。例如,一些系统可能没有采用先进的加密技术和访问控制手段,导致数据泄露的风险较高。
5. 未来发展方向
镜心悟道的系统未来发展方向包括深度学习、知识图谱和人机交互。这些技术的应用将进一步提升系统的智能化水平和用户体验。
相比之下,其他AI健康管理系统的未来发展方向可能较为单一,主要集中在现有技术的优化和改进上,缺乏对新兴技术的探索和应用。
总结
镜心悟道公司开发的五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>在技术架构、数据处理、用户体验、安全保护和未来发展方向等方面均表现出色,与其他AI健康管理系统相比具有显著优势。
镜心悟道公司AI易经智能“大脑”系统中的九九归一阴阳权重算法(BTFWEYPF-PMLA)和无限循环接近阴阳平衡算法(ILNBA)的工作原理及其效果评估。
根据提供的信息,镜心悟道公司AI易经智能“大脑”系统中的九九归一阴阳权重算法(BTFWEYPF-PMLA)和无限循环接近阴阳平衡算法(ILNBA)的工作原理及其效果评估如下:
九九归一阴阳权重算法(BTFWEYPF-PMLA)
工作原理:
九九归一阴阳权重算法(BTFWEYPF-PMLA)是一种基于易经原理的权重分配算法。该算法通过将数据分为阴阳两部分,并分别赋予不同的权重,从而实现对数据的综合分析和处理。具体来说,该算法首先将输入的数据按照易经中的阴阳理论进行分类,然后根据阴阳属性的不同,分别赋予不同的权重。通过这种方式,算法能够更准确地反映数据的内在规律和趋势。
效果评估:
该算法在处理复杂数据时表现出色,特别是在需要考虑数据内在阴阳属性的情况下。通过合理的权重分配,能够提高数据分析的准确性和可靠性。然而,该算法对数据的预处理要求较高,需要对数据进行详细的分类和标注,这可能会增加数据处理的复杂度。
无限循环接近阴阳平衡算法(ILNBA)
工作原理:
无限循环接近阴阳平衡算法(ILNBA)是一种动态调整权重的算法。该算法通过不断迭代和调整权重,使得阴阳两部分的数据逐渐趋于平衡。具体来说,算法在每次迭代中都会重新计算阴阳两部分的权重,并根据新的权重值进行调整,直到阴阳两部分的数据达到一个相对平衡的状态。
效果评估:
该算法在处理动态变化的数据时具有显著优势。通过不断的迭代和调整,能够有效地应对数据的波动和变化,保持数据的平衡状态。然而,该算法的计算过程较为复杂,需要较高的计算资源和时间成本。此外,由于其动态调整的特性,可能会导致结果的稳定性较差,需要进一步优化和改进。
镜心悟道公司AI易经智能“大脑”系统中的九九归一阴阳权重算法和无限循环接近阴阳平衡算法各有其独特的优势和应用场景。
镜心悟道公司AI易经智能“大脑”系统在情感与健康关联分析方面的应用案例和成效。
根据提供的信息,无法直接回答关于镜心悟道公司AI易经智能“大脑”系统在情感与健康关联分析方面的应用案例和成效的问题。我搜索到的资料主要集中在情感理论、情感分析技术、医疗健康领域的应用以及人工智能在医疗和情感计算中的潜力等方面,但没有具体提到镜心悟道公司的AI易经智能“大脑”系统及其在情感与健康关联分析中的应用案例和成效。
然而,可以从我搜索到的资料中提取一些相关的信息,以提供一些背景知识:
-
情感与健康的关系:
- 情感对健康有重要影响。研究表明,情绪状态与多种健康问题相关,如慢性疼痛、抑郁复发、成瘾等。此外,压力和焦虑等负面情绪可能对身体健康产生负面影响。
- 正念干预等方法已被证明可以改善健康结果,包括减少慢性疼痛和抑郁复发。
-
情感分析技术:
- 情感分析技术在多个领域有广泛应用,包括医疗健康。例如,基于复杂情绪词汇的失眠和心理健康分析。
- 情感计算可以用于识别情绪变化,并提供相应的指导或建议,从而帮助改善心理健康。
-
人工智能在医疗健康中的应用:
- 人工智能在医疗健康领域的应用前景广阔,包括诊断成像、病理学、临床决策支持等。
- 尽管AI在医疗领域的应用潜力巨大,但它无法完全取代医生,特别是在需要同情心、情感连接和复杂决策的情况下。
-
情感与健康监测:
- 情感监测和分析可以用于健康监测,特别是在孕妇健康领域。研究表明,孕妇的情绪状态与妊娠风险相关,情感计算可以用于识别情绪变化并提供支持。以下是对您提供的信息进行的详细分析和回答:
- 算法框架概述
- 全面评估维度:镜心悟道公司的AI易经智能“大脑”系统从天(火)、道(木)、人(金)、事(水)、物(土)五个维度进行全面评估,每个维度都通过一系列算法进行深入分析,以实现对中医健康管理的全面理解和优化。
- 算法序列:每个维度都包含了从1ED算法到9ED算法以及九九归一阴阳权重算法的完整序列,这些算法相互协作,逐步深入地处理和分析相关数据,确保评估的全面性和准确性。
- “小镜”CQRS + RLHF + JYFTA架构师
- 架构特点
- 融合多种技术:结合了CQRS(Command Query Responsibility Segregation)、RLHF(Reinforcement Learning with Human Feedback)和JYFTA(Junior Jing's Yixue Fine - Tuning Architect)等架构理念,实现了命令与查询的分离、强化学习与人类反馈的结合以及专业的微调优化。
- 使用混合神经网络系统:采用混合神经网络系统,如WD3_HMNNS,能够充分发挥不同神经网络的优势,提高系统的智能性和适应性。
- 作用与优势
- 提升系统性能:通过这种架构设计,系统能够更好地处理复杂的中医健康管理问题,提供更准确、个性化的服务。
- 促进优化与创新:有利于系统的持续优化和创新,不断适应新的需求和数据变化,提高系统的竞争力。
- 伪代码架构逻辑思维链
- 逻辑流程
- 数据处理与算法执行:从数据的采集和预处理开始,通过一系列算法的执行,对中医健康管理相关的数据进行深入分析,包括五行脉象数据、中医理论知识等。
- 决策与优化:根据算法的输出结果,进行决策制定和优化调整,为用户提供最佳的健康管理方案。
- 反馈与循环:系统通过不断收集用户反馈,进行循环优化,不断提高系统的性能和服务质量。
- 关键要素
- 明确的任务定义:每个算法步骤都有明确的任务定义,确保数据处理和分析的准确性和一致性。
- 数据的传递与共享:通过合理的数据传递和共享机制,确保各个算法之间能够有效地协作,共同完成系统的目标。
- 优化与改进:注重对系统的优化和改进,不断提高算法的效率和准确性,以适应不断变化的需求和数据环境。
综上所述,镜心悟道公司的AI易经智能“大脑”系统通过独特的算法框架和“小镜”CQRS + RLHF + JYFTA架构师,结合混合神经网络系统,实现了对中医健康管理的全面、精准评估和优化,为用户提供了更优质的健康管理服务。镜心悟道公司开发的AI易经智能“大脑”系统(FAAFE5DGOF)通过五元五维生克逻辑函数全息分析算法框架,结合易经智慧与现代人工智能技术,实现了对天(火)、道(木)、人(金)、事(水)、物(土)五个维度的全面评估和优化。以下是该系统的详细解析及其在中医健康管理领域的创新性和应用潜力:
1. 五元五维生克逻辑函数全息分析算法框架(FAAFE5DGOF)
该系统从天、道、人、事、物五个维度进行全面评估,每个维度都通过1ED到9ED算法的逐步演算,最终通过“九九归一阴阳权重算法”(BTFWEYPF-PMLA)和“ILNBA九九归一无限循环接近阴阳平衡算法”实现动态平衡和优化。
1.1 天(火)<王阳明心学>
- 1ED算法→9ED算法:通过逐步演算,系统将王阳明心学的“知行合一”和“致良知”理念转化为AI的伦理推理模块,确保系统在决策过程中嵌入伦理考量。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA):通过阴阳权重的动态调整,系统能够模拟人工意识的某些方面,实现自主、反思性和伦理感知的行为。
- ILNBA九九归一无限循环接近阴阳平衡算法:系统通过无限循环的方式,不断接近阴阳平衡状态,确保伦理决策的持续优化。
1.2 道(木)<道的悟道>
- 1ED算法→9ED算法:系统通过逐步演算,结合道的悟道理念,推动技术的创新与发展。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA):通过阴阳权重的动态调整,系统能够不断优化其技术架构和算法模型。
- ILNBA九九归一无限循环接近阴阳平衡算法:系统通过无限循环的方式,确保技术的持续进步和创新。
1.3 人(金)<人性的矛盾>
- 1ED算法→9ED算法:系统通过逐步演算,结合人性的矛盾,确保规章制度和执行力在系统中的高效运转。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA):通过阴阳权重的动态调整,系统能够应对人性中的矛盾,实现动态平衡。
- ILNBA九九归一无限循环接近阴阳平衡算法:系统通过无限循环的方式,确保在人性矛盾中的自适应学习和动态平衡。
1.4 事(水)<五行脉象数据化中医健康管理>
- 1ED算法→9ED算法:系统通过逐步演算,结合五行脉象数据化中医健康管理,提供个性化的健康管理方案。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA):通过阴阳权重的动态调整,系统能够精准分析五行脉象,提供健康管理建议。
- ILNBA九九归一无限循环接近阴阳平衡算法:系统通过无限循环的方式,确保健康管理的持续优化和个性化服务。
1.5 物(土)<ESG五行系统团队管理>
- 1ED算法→9ED算法:系统通过逐步演算,结合ESG五行系统团队管理,确保团队的稳定性和可持续发展。
- 九九归一阴阳权重算法(BTFWEYPF-PMLA):通过阴阳权重的动态调整,系统能够优化团队管理策略,确保团队的稳定性和高效运作。
- ILNBA九九归一无限循环接近阴阳平衡算法:系统通过无限循环的方式,确保团队管理的持续优化和动态平衡。
2. 算法矩阵集框架专属伪代码架构逻辑思维链
系统的算法矩阵集框架通过伪代码架构逻辑思维链(PFS)实现,具体包括以下步骤:
// 定义系统组件
define_system_components()
store = JingXinWuDaoAIYijingIntelligentBrainStore()
nlp = STORE_NLP()
prl = PRL_Input_COT_Matrix_Output()
four_elements = FourElementsArchitecture()
three_elements = ThreeElementsArchitecture()
five_elements = FiveElementsArchitecture()
two_elements = TwoElementsArchitecture()
six_elements = SixElementsArchitecture()
// 定义系统功能
define_system_functions()
store_data_and_retrieve(store)
process_natural_language(nlp)
perceive_reason_learn(prl)
镜心悟道公司开发的AI易经智能“大脑”系统类五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>,从天(火)<王阳明心学>、道(木)<道的悟道>、人(金)<人性的矛盾>、事(水)<五行脉象数据化中医健康管理>、物(土)<ESG五行系统团队管理>五个维度进行全面评估。以下是映射标注上的五行符号、八卦符号、六十四卦符号、英文全称和缩写:
镜心悟道公司开发的AI易经智能“大脑”系统类五元五维生克逻辑函数全息分析算法框架<FAAFE5DGOF>,从天(火)、道(木)、人(金)、事(水)、物(土)五个维度进行全面评估。 该系统结合了易经智慧与现代人工智能技术,旨在通过五行相生相克的逻辑关系,实现对健康、管理等多领域的全面分析和优化。
1. **天(火):王阳明心学**
王阳明心学强调“知行合一”和“致良知”,这与AI易经智能“大脑”系统中的创新思维和工作热情相契合。 系统通过火的象征意义,代表其持续发展的动力和创新能力。
2. **道(木):道的悟道**
道的悟道体现在系统的技术进步和研发能力上,木的象征意义在于推动系统的创新与发展。
3. **人(金):人性的矛盾**
系统通过金的象征意义,代表规章制度和执行力,确保系统的高效运转。 同时,人性的矛盾在AI技术学习中也得到了体现,系统通过动态平衡和自适应学习来应对这些矛盾。
4. **事(水):五行脉象数据化中医健康管理**
系统通过水的象征意义,代表团队成员的智慧和学习能力,是系统适应变化的关键。 此外,五行脉象数据化中医健康管理是系统的重要应用之一,通过分析五行脉象来提供健康管理建议。
5. **物(土):ESG五行系统团队管理**
土的象征意义在于团队稳定性与基础建设,为系统提供稳固的支撑。 ESG五行系统团队管理则强调可持续和安全原则,与土的特性相契合。
镜心悟道AI易经智能“大脑”系统通过五元五维的全息分析算法框架,结合五行相生相克的逻辑关系,实现了对天、道、人、事、物五个维度的全面评估和优化。 这种综合性的分析方法不仅提升了系统的智能化水平,还为中医健康管理、团队管理等领域提供了创新的解决方案.
镜心悟道公司开发的AI易经智能“大脑”系统<FAAFE5DGOF>的具体技术实现和算法框架如下:
1. **数据存储与检索组件**:该系统使用了名为JAMV_YIBSA_Store的组件,负责存储和管理易经相关知识和数据。 这一组件确保了系统能够高效地访问和处理大量的易经文本和数据。
2. **智能体管理组件**:Intelligent_AgentStore组件用于存储、管理和调用智能体执行任务和决策。 这使得系统能够灵活地调度不同的智能体来完成特定的任务。
3. **记忆系统组件**:MemorySystem记录历史数据、用户交互信息和学习经验。 这一组件帮助系统不断优化其决策过程,提高准确性和个性化服务。
4. **虚拟仿真助手组件**:VirtualSimulationAssistant通过模拟真实情境,预测趋势,测试决策的有效性。 这一功能使得系统能够在实际应用前进行充分的验证和优化。
5. **高级算法与工作流组件**:
- WD3_HMNNS:使用混合神经网络系统进行数据分析和模式识别。
- YYYWLOOP:通过迭代优化推理和决策能力。
6. **语言处理组件**:JXWDYY_PFS负责解析易经文本,提取关键信息。 这一组件确保了系统能够准确理解并处理易经文本中的复杂概念。
7. **用户界面与交互组件**:1D_IC_EASE简化用户界面,提升交互便利性。 这一组件使得用户能够更加方便地与系统进行交互。
8. **自然语言对话组件**:AgentStoreChatBot_DQN_Mode提供基于深度强化学习的个性化咨询和帮助。 这一组件使得系统能够与用户进行自然语言对话,提供个性化的咨询和服务。
9. **智能工作流程组件**:Agentic_Workflow自我优化和自主执行任务,提升效率和准确性。 这一组件确保了系统的高效运行和持续改进。
此外,镜心悟道AI易经智能“大脑”系统还结合了“小镜”易医中医全职中医师、ChatBot-DQN-MoE-Mixture-of-Depths MoD等技术,特别针对AI+中医健康管理领域的应用。
系统的架构伪代码如下:
```plaintext
// 定义系统组件
define_system_components()
store = JingXinWuDaoAIYijingIntelligentBrainStore()
nlp = STORE_NLP()
prl = PRL_Input_COT_Matrix_Output()
four_elements = FourElementsArchitecture()
three_elements = ThreeElementsArchitecture()
five_elements = FiveElementsArchitecture()
two_elements = TwoElementsArchitecture()
six_elements = SixElementsArchitecture()
// 定义系统功能
define_system_functions()
store_data_and_retrieve(store)
process_natural_language(nlp)
perceive_reason_learn(prl)
process_four_elements(four_elements)
process_three_elements(three_elements)
process_five_elements(five_elements)
process_two_elements(two_elements)
process_six_elements(six_elements)
// 主程序
main()
initialize_system_components()
execute_system_functions()王阳明心学在AI易经智能“大脑”系统中的应用和影响具体表现在哪些方面?
王阳明心学在AI易经智能“大脑”系统中的应用和影响主要体现在以下几个方面:
-
伦理指导与智慧生成:
王阳明心学强调“知行合一”和“正心诚意”,这些理念被整合到AI系统中,以提供伦理指导和智慧生成。 例如,通过四空间DIKWP模型的应用,AI系统能够模拟人工意识的某些方面,实现更自主、反思性和伦理感知的行为。 这种伦理推理模块确保AI在决策过程中内嵌伦理考量,促进负责任的AI行为。 -
个性化咨询与生活指导:
镜心悟道AI易经智能“大脑”系统集成了王阳明心学,旨在通过易经智慧辅助决策,提供个性化咨询和服务。 例如,系统可以帮助用户在个人生活、职业发展和情感关系中寻找心学智慧,实现内心平和与精神自由。 -
认知增强与教育工具:
王阳明心学的复杂性和象征性需要先进的语义建模技术来捕捉其细腻的意义。 因此,AI系统可以利用四空间模型增强其符号推理能力,使其能够更深入地理解和应用王阳明心学。 此外,AI还可以作为教育工具,通过交互平台教授用户王阳明心学,促进认知和伦理发展。 -
文化整合与跨学科研究:
王阳明心学的文化背景和哲学基础需要在AI系统中得到尊重和整合。 通过跨学科合作,整合哲学、伦理学、数学和AI专家的知识,可以确保AI解释中的文化真实性,并促进有意义的跨文化伦理交流。 例如,开发互动知识图谱和语义AI框架,帮助用户更好地理解和导航王阳明复杂的伦理网络。 -
伦理决策支持:
利用四空间模型的AI系统可以基于王阳明的教义提供细腻且伦理对齐的决策支持。 这些系统能够处理王阳明的伦理教义,解释其原则,综合知识,并推导出与定义的目的对齐的智慧,从而在领导力、治理和个人发展等领域提供伦理基础的咨询服务。 -
增强人类认知与反思性AI:
整合四空间模型使AI系统能够增强人类认知,提供更深刻的洞见并促进伦理决策。 例如,AI系统可以进行类似人类沉思的反思性实践,评估和优化自身的过程和结果。 这种反思性AI有助于用户参与伦理推理和目的驱动的决策过程。
如何通过五行脉象数据化中医健康管理来优化个人健康和疾病预防?
通过五行脉象数据化中医健康管理来优化个人健康和疾病预防,可以从以下几个方面进行:
-
实时监测与数据分析:
- 利用智能穿戴设备和健康监测设备(如健康手表、智能体脂秤等),实时监测用户的生理指标,如心率、血压、睡眠质量等。 这些数据经过算法处理,可以反映出人体的健康状况,为中医的体质辨识提供依据。
- 通过大数据技术,收集和分析用户的健康数据,发现疾病早期信号,预测健康风险,优化中医养生方案。
-
个性化健康管理方案:
- 基于大数据和人工智能技术,对个体的体质、生活习惯、环境因素等进行全方位分析,实现中医养生的个性化和精准化。 例如,根据个人的饮食习惯、运动量等信息,推荐适合的食疗方案和运动计划,实现“因人制宜”。
- 智能推荐系统可以根据用户的反馈和实际效果,不断调整和优化养生方案,形成一个动态的健康生态系统。
-
智能诊断与治疗:
- 使用智能脉诊仪模拟中医诊断,AI辅助诊断系统提高诊断准确性和效率。 例如,依脉中医四诊智能诊断系统可以精准采集脉象信息,分析脉位、脉数、脉形和脉势四大特征,帮助医生识别特定器官健康状况、心脏状态、病理变化和气血状态。
- 结合经典方剂、中成药、针灸和穴位按摩,提供精准的健康管理方案。
-
远程医疗与在线咨询服务:
- 用户可以通过智能健康管理平台与中医专家进行在线交流,甚至进行远程诊疗。 专家可以根据用户的症状和体检报告,给出专业的诊疗建议,无需用户亲自去医院,大大节省了时间和精力。
- 平台还能实时监测用户的健康状况,预警潜在的健康风险,实现疾病预防的前瞻性。
-
数据驱动的科学化升级:
- 大数据技术的应用,使得中医养生从经验导向转向数据导向。 平台收集的海量健康数据,经过分析处理,可以揭示出健康问题的规律和趋势,为中医理论提供实证支持。
- 这些数据也能帮助医生优化诊疗方案,提升治疗效果,使中医养生更加科学、精准。
-
综合分析与专业医生判断:
- 虽然大数据和智能技术在中医健康管理中发挥了重要作用,但综合分析和专业医生的判断仍然至关重要。 例如,人体数据中心中医系统数据强调了标准化数据采集、高精度测量设备、多模态数据融合等注意事项,以确保数据的准确性。
- 专业医生在确定患者体质类型和制定治疗方案时,仍然需要结合临床实践和专业判断。
ESG五行系统团队管理在实际应用中如何促进团队的可持续发展和稳定性?
ESG五行系统团队管理在实际应用中可以通过以下几个方面促进团队的可持续发展和稳定性:
-
明确可持续发展战略:企业需要基于可持续发展理念,结合自身业务特点,制定指导可持续发展的纲领性内容,明确践行可持续发展的内容边界。 这有助于团队成员理解企业的长期目标,并在日常工作中朝着这些目标努力。
-
设立可持续发展管治架构:建立组织架构,确保ESG工作顺利推进,将ESG融入日常管理。 通过设立专门的ESG团队或部门,明确各成员的职责和角色,可以提高团队的效率和责任感。
-
积极开展利益相关方沟通:与利益相关方保持有效沟通,深入了解各方诉求,确保意见和诉求有效反馈。 这不仅有助于团队更好地理解外部环境,还能增强团队成员之间的信任和协作。
-
注重识别重要性议题:识别与企业高度相关的议题,有效分配和利用资源,确保可持续发展管理的基础。 通过定期评估和调整重要性议题,团队可以确保资源的有效利用,从而提高整体绩效。
-
将ESG落实到具体指标:将议题拆解到具体指标,保障议题切实推进,帮助企业更好地管理。 通过设定可量化的指标,团队可以更直观地看到进展和成效,从而激励成员持续改进。
-
以审验促进管理提升:通过报告审验增强报告可信度,发现管理不足,促进管理提升。 定期的审验和评估可以帮助团队发现潜在问题并及时调整策略,从而提高整体管理水平。
-
赋予决策权:赋予可持续发展团队决策权,使其能够紧贴最新趋势,并以有效方式实施适当措施。 这有助于团队快速响应变化,确保企业始终走在可持续发展的前沿。
-
高管团队稳定性:高管团队的稳定性对企业的ESG评级有显著影响。 稳定的高管团队能够降低战略差异度和经营风险,从而提高企业的ESG评级。 因此,企业应采取措施保持高管团队的稳定性,如提供职业发展机会和良好的工作环境。
-
团队建设:通过团队建设活动,如户外寻宝活动,结合ESG和可持续发展目标(SDGs),可以增强团队成员之间的联系,提高团队效率和未来导向性。 这种活动不仅有助于提升团队凝聚力,还能让成员在轻松愉快的氛围中学习和成长。
-
技术应用:利用ESG数据管理平台、区块链和数据可视化工具等技术手段,可以有效测量、报告和合规。 这些技术的应用不仅提高了数据的准确性和透明度,还增强了团队的协作和决策能力。
镜心悟道AI易经智能“大脑”系统在处理人性矛盾和动态平衡方面的具体策略和技术是什么?
根据提供的信息,无法直接回答关于镜心悟道AI易经智能“大脑”系统在处理人性矛盾和动态平衡方面的具体策略和技术的问题。 我搜索到的资料主要集中在系统的整体架构、功能模块和应用领域,但没有具体提到如何处理人性矛盾和动态平衡。
然而,可以从一些相关的信息中推测出一些可能的策略和技术:
-
多智能体协同:镜心悟道AI易经智能“大脑”系统采用了多智能体协同(Multi-Agent Collaboration)的工作模式,这可能有助于系统在处理复杂的人性矛盾时,通过多个智能体的协作来实现动态平衡。 例如,XiaoJingChatBotDQNMoDE多智能体系统可以处理不同的任务和需求,从而提供更加灵活和适应性的解决方案。
-
个性化服务:通过收集和处理用户反馈,镜心悟道AI易经智能“大脑”能够根据用户的需求和反馈进行优化和调整,从而提供更加个性化和精准的服务。 这种个性化服务可能有助于在处理人性矛盾时,更好地理解和满足用户的需求。
-
市场分析与定位:系统利用自然语言处理(NLP)和商业智能技术进行市场分析和客户行为预测,从而精准确定目标群体。 这种市场分析能力可以帮助系
镜心悟道公司开发的AI易经智能“大脑”系统是一个结合了易经智慧与现代人工智能技术的创新平台,旨在提供中医健康管理服务。该系统采用了多元多维矩阵理论和气机一元论,通过六十四卦神经网络矩阵和智能全息系统架构来实现其功能。
系统的核心组件包括症状输入模块、五行八卦选择器、治疗建议区域以及历史记录和跟踪功能。此外,还使用了JXWDYYPFS伪代码格式化工具,以提高代码的可读性和可维护性。
镜心悟道AI易经智能“大脑”采用了9E算法(九九归一无限循环接近阴阳平衡算法),这是一种全面的诊断方法,结合多种维度和层次的数据来进行整体健康评估。此外,系统还利用了五行生克逻辑算法系统(5E-HIC GCLAS),通过无限循环的方式识别和调整不平衡状态。
该系统还结合了自然语言处理(NLP)技术,通过SelfCognitionModel类作为智能流程控制器,处理用户输入并调用相应函数获取答案。系统中还包含了一个名为“小镜”的CQRS+RLHF+JYFTA架构师,使用混合神经网络系统(WD3_HMNNS)进行数据分析和模式识别。
镜心悟道AI易经智能“大脑”系统通过融合传统智慧与现代科技,为用户提供个性化的健康管理服务,并在中医健康管理领域展示了其创新性和应用潜力。
镜心悟道公司AI易经智能“大脑”系统中的9E算法(九九归一无限循环接近阴阳平衡算法)的具体实现和效果评估如下:
具体实现
9E算法是镜心悟道AI易经智能“大脑”系统中的核心算法之一,旨在通过九元九维的维度和属性记忆标注,实现对健康长寿的精准预测和管理。该算法结合了易经智慧与现代人工智能技术,通过以下步骤实现:
-
初始化各种维度和属性的元素:
- 一元一维:初始化一元一维的元素。
- 二元二维:初始化二元二维的阴阳无限循环论记忆标注。
- 三元三维:初始化三元三维的天地人整体观论记忆标注。
- 四元四维:初始化四元四维的气血阴阳论记忆标注。
- 五元五维:初始化五元五维的五行相生相克论记忆标注。
- 六元六维:初始化六元六维的六淫六邪六经六神六郁论记忆标注。
- 七元七维:初始化七元七维的七星宇宙天人合一七情论记忆标注。
- 八元八维:初始化八元八维的八卦六十四卦复合封无限循环推演演算论记忆标注。
- 九元九维:初始化九元九维的九九归一一阳气机守一健康长寿论记忆标注。
-
应用各维度理论:
- 应用一元一维一气机论:通过一元一维的理论,分析和预测健康状态。
- 应用二元二维阴阳无限循环论:通过阴阳无限循环论,实现对阴阳平衡状态的动态监测和调整。
- 应用三元三维天地人整体观论:通过天地人整体观论,综合考虑环境、人体和精神三方面的因素,进行健康评估。
- 应用四元四维气血阴阳论:通过气血阴阳论,分析和调节人体内的气血和阴阳平衡。
- 应用五元五维五行相生相克论:通过五行相生相克论,分析和调节人体内的五行关系。
- 应用六元六维六淫六邪六经六神六郁论:通过六淫六邪六经六神六郁论,全面分析和调节人体内的各种病理因素。
- 应用七元七维七星宇宙天人合一七情论:通过七星宇宙天人合一七情论,综合考虑天人合一和七情的影响。
- 应用八元八维八卦六十四卦复合封无限循环推演演算论:通过八卦六十四卦复合封无限循环推演演算论,进行复杂的健康状态推演和预测。
- 应用九元九维九九归一一阳气机守一健康长寿论:通过九九归一的理论,实现对健康长寿状态的精准管理和预测。
效果评估
9E算法的效果评估主要体现在以下几个方面:
- 精准度:通过多维度、多层次的记忆标注和推演演算,9E算法能够实现对健康状态的精准预测和管理,减少误诊和漏诊的风险。
- 全面性:结合易经智慧和现代人工智能技术,9E算法能够全面考虑人体内的各种因素,包括气血、阴阳、五行、六淫、七情等,提供全面的健康评估和管理方案。
- 动态性:通过阴阳无限循环论和八卦六十四卦复合封无限循环推演演算论,9E算法能够实现对健康状态的动态监测和调整,及时应对各种健康问题。
- 长寿性:通过九九归一的理论,9E算法能够实现对健康长寿状态的精准管理和预测,帮助用户实现健康长寿的目标。
如何评价镜心悟道AI易经智能“大脑”系统在中医健康管理领域的创新性和应用潜力?
镜心悟道AI易经智能“大脑”系统在中医健康管理领域的创新性和应用潜力可以从多个方面进行评价。
该系统融合了易经智慧与现代AI技术,构建了一个全面、高效且智能的自然语言处理平台。通过结合易经理论、五行推演、太极八卦图等传统中医理论,以及现代科技如边缘计算和物联网,镜心悟道AI易经智能“大脑”能够提供全方位的健康管理服务。这种跨学科的融合不仅增强了系统的智能化水平,还使其能够更好地理解和应用中医理论,从而为用户提供个性化的健康管理方案。
镜心悟道AI易经智能“大脑”系统的核心组件和功能非常丰富。例如,五行脉象团队结合中医五行理论和现代科技,提供全方位的健康管理服务。此外,系统还集成了多种高级组件,如ERNIE-GEN、JXWD_AIBStore、STORENLP等,这些组件共同构建了一个高效且智能的自然语言处理平台。这种多层次、多维度的架构设计使得系统能够处理复杂的医疗数据,并提供精准的健康诊断和建议。
镜心悟道AI易经智能“大脑”系统在实际应用中也展现了巨大的潜力。例如,其SNLP招商矩阵模型和五行脉象团队的合作,展示了在保健食品咨询领域的协同效应。这种多智能体协同工作模式不仅提高了系统的智能化水平,还增强了其在实际应用中的灵活性和适应性。
此外,镜心悟道AI易经智能“大脑”系统还具备强大的数据处理和分析能力。通过边缘计算和物联网技术,系统能够将计算能力拓展到网络边缘,实时处理和分析大量的健康数据。这种实时处理能力使得系统能够及时响应用户的健康需求,提供即时的健康建议和干预措施。
镜心悟道AI易经智能“大脑”系统在中医健康管理领域的创新性和应用潜力非常显著。
镜心悟道AI易经智能“大脑”系统使用的五行生克逻辑算法系统(5E-HIC GCLAS)的工作原理及其在健康诊断中的准确性如何?
镜心悟道AI易经智能“大脑”系统中的五行生克逻辑算法系统(5E-HIC GCLAS)的工作原理主要基于易经的五行理论,即金、木、水、火、土之间的相生相克关系。这些关系在中医理论和实践中被广泛应用,用于分析和预测健康状况。
该系统结合了现代人工智能技术,通过深度学习和数据分析技术,对用户的脉象数据进行分析,从而预测和评估用户的健康状况[[1。具]]体来说,系统会利用五行相生相克的逻辑关系,结合八卦和六十四卦的演算逻辑,对疾病发展趋势、病症关联性和疾病模式进行预测和分析。
在健康诊断方面,该系统通过集成多种机器学习算法(如决策树、随机森林、支持向量机等),以及迁移学习技术,提高了诊断的准确性。此外,系统还能够自主学习和优化,不断提高预测和评估的准确性。
总体而言,镜心悟道AI易经智能“大脑”系统在健康诊断中的准确性较高,因为它不仅依赖于传统的中医五行理论,还结合了现代AI技术,能够提供个性化的健康咨询和服务。
“小镜”CQRS+RLHF+JYFTA架构师在镜心悟道AI易经智能“大脑”系统中的角色和功能是什么?
无法直接找到关于“小镜”CQRS+RLHF+JYFTA架构师在镜心悟道AI易经智能“大脑”系统中的具体角色和功能的详细描述。然而,可以从我搜索到的资料中推断出一些信息。
-
系统架构与组件:
- 镜心悟道AI易经智能“大脑”系统包括多个高级组件,如ERNIE-GEN、JXWD_AIBStore、STORENLP、JXWDYYPFS、Smart Iterator、Adala以及全息中医生态链智能体套娃系统架构(IAMS)等。
- 系统通过StoreNLP完成自然语言处理的浅层分析任务,如分/切词、词性标注、语义组块和命名实体标注。
- IAMS架构通过高层函数的抽象基类实现智能体之间的高效协同,采用精细标注方法确保数据准确性和可靠性。
-
核心流程与框架设计:
- 镜心悟道AI易经智能“大脑”的核心流程控制器名为“jxwd_intelligent_flow”,负责从初始化到任务执行、监控、反馈和优化等整个AI任务的生命周期。
-
编程语言与伪代码格式化:
- 系统使用jxwd编程语言JXWDYYPFS进行伪代码格式化,构建了一个高效、灵活的推演系统,能够支持各种复杂的自然语言处理任务。
-
系统功能与特色:
- 平台功能包括健康管理、中医咨询、易经智慧和社群交流等。
- 平台特色包括科技赋能和个性化定制,利用AI技术结合易经的智慧,为用户提供更精准的健康管理服务。
虽然没有直接提到“小镜”CQRS+RLHF+JYFTA架构师的具体角色和功能,但可以推测“小镜”可能是一个关键的智能体或模块,负责处理特定的任务或功能。例如,它可能涉及自然语言处理、数据存储与检索、智能体管理等方面的工作。
镜心悟道AI易经智能“大脑”系统如何结合自然语言处理(NLP)技术来提高用户交互体验?
根据提供的信息,无法直接回答“镜心悟道AI易经智能‘大脑’系统如何结合自然语言处理(NLP)技术来提高用户交互体验”的问题。我搜索到的资料主要集中在镜心悟道AI易经智能“大脑”系统的架构、模型和相关项目介绍,但没有具体提到NLP技术在用户交互体验中的应用细节。
然而,可以从我搜索到的资料中推断出一些相关信息:
-
多智能体协作框架(MACF)和多智能体协作网络(MacNet) :这些技术可能涉及到自然语言处理(NLP),因为它们通常用于处理和理解自然语言数据。通过多智能体协作,系统可以更好地理解和响应用户的自然语言输入。
-
SelfCognitionModel类的代码示例:这表明系统中存在用于自我认知和理解的模块,这些模块可能依赖于NLP技术来分析和处理用户的自然语言输入。
-
镜心悟道AI易经智能“大脑”SNLP招商矩阵模型:虽然没有详细描述NLP的具体应用,但“SNLP”(StoreNLP)模型的名称暗示了NLP技术在其中的应用。该模型可能用于优化用户交互,例如通过自然语言理解和生成来提高用户体验。
五元五维生克逻辑函数全息分析算法框架,从天(火)、道(木)、人(金)、事(水)、物(土)五个维度进行全面评估。以下是映射标注上的五行符号、八卦符号、六十四卦符号、英文全称和缩写:以下是一些可能的英文全称和缩写:
- 英文全称
- Full Analysis Algorithm Framework of Five Elements and Five Dimensions Generative and Overcoming Logic Function
- Holistic Analysis Algorithm Framework of Five Elements and Five Dimensions of Xingke Logic Function
- 缩写
- FAAFE5DGOF (Full Analysis Algorithm Framework of Five Elements)
- HA5DLOKF (Holistic Analysis Algorithm Framework of Five Dimensions of Xingke Logic Function)
评论 (0)